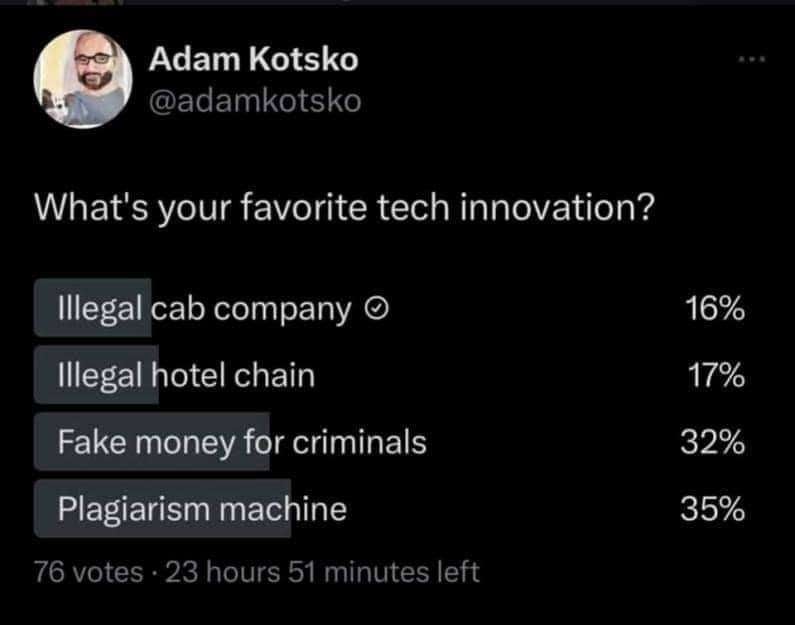
OpenAI Pleads That It Can’t Make Money Without Using Copyrighted Materials for Free
OpenAI Pleads That It Can’t Make Money Without Using Copyrighted Materials for Free
OpenAI is begging Parliament to allow it to use copyrighted works because it's "impossible" for the company to make money without them.

Then it sounds like your business is a failure and should be shutdown.
WHO is the one guy who downvotes you???
"NO! UNPROFITABLE BUSINESSES DESERVE TO THRIVE!!! MUST FEED THE BILLIONAIRES!!!"
Maybe OpenAI learned to downvote...
There are some hardcore "copyright shouldn't exist" folks out there.
The guy who wants their AI girlfriend yesterday.
WHO is the one guy who downvotes you???
That's the bot that ChatGPT operates here on Lemmy.
Sam Altman lurking around...
To steel man the downvoters, maybe there are other solutions besides killing off every business that can't afford to comply with copyright. After all, isn't the whole point of copyright to enable the capitalist exploitation of information?
Lol how about every pirate who fundamentally opposes the copyright system?
How about everyone who uses Google and doesn't want to see it shut down for scraping copyrighted content to provide a search engine?
Seriously, explain to me what's different at a fundamental level about OpenAI scraping the web and transforming the data through an LLM and Google scraping the web and transforming the data through their algorithms (which include LLMs)?
If not, The Pirate Bay would like a word.
I'd love to see how scared some big companies would be if we could decriminalize piracy
Honestly this meme is way understating the sinisterness
- Election interference for money machine
- Whole internet is ads company
- Dopamine addiction for all children
- Superpowers for law enforcement
Yeah! I can't make money running my restaurant if I have to pay for the ingredients, so I should be allowed to steal them. How else can I make money??
Alternatively:
OpenAI is no different from pirate streaming sites in this regard (loosely: streaming sites are way more useful to humanity). If OpenAI gets a pass, so should every site that's been shut down for piracy.
If OpenAI wants a pass, then just like how piracy services make content freely open and available, they should make their models open.
Give me the weights, publish your datasets, slap on a permissive license.
If you're not willing to contribute back to society with what you used from it, then you shouldn't exist within society until you do so.
This is actually a very good comparison because restaurants use this argument all the time, except for wages:
"I can't make money running my restaurant if I have to pay a living wage to my servers, so you should pay them with tips. How else can we stay open?"
These business that can't operate profitably like any other business should fail.
In China, tipping is considered insulting because you are implying exactly that: that they are incapable of running their business without your donation.
K, so Google should be shut down too?
They can't operate without scraping copyrighted data.
This is a false equivalency.
Google used to act as a directory for the internet along with other web search services. In court, they argued that the content they scrapped wasn't easily accessible through the searches alone and had statistical proof that the search engine was helping bring people to more websites, not preventing them from going. At the time, they were right. This was the "good" era of Google, a different time period and company entirely.
Since then, Google has parsed even more data, made that data easily available in the google search results pages directly (avoiding link click-throughs), increased the number of services they provide to the degree that they have a conflict of interest on the data they collect and a vested interest in keeping people "on google" and off the other parts of the web, and participated in the same bullshit policies that OpenAI started with their Gemini project. Whatever win they had in the 2000s against book publishers, it could be argued that the rights they were "afforded" back in those days were contingent on them being good-faith participants and not competitors. OpenAI and "summary" models that fail to reference sources with direct links, make hugely inaccurate statements, and generate "infinite content" by mashing together letters in the worlds most complicated markov chain fit in this category.
It turns out, if you're afforded the rights to something on a technicality, it's actually pretty dumb to become brazen and assume that you can push these rights to the breaking point.
In every other circumstance I can think of, “I can’t make money doing a thing unless I break the law” means don’t do that thing.
Why should AI get special treatment?
Well in almost every other circumstance, you’re forgetting Uber and Airbnb.
Because they already raised hundreds of millions from investors
Because black numbers going up make shareholders happy
The more the original work is transformed, the more likely it is to be considered fair use rather than infringement.
Cool. If OpenAI gets a pass, then piracy should be legal, right? I mean what good is a trademark or copyright law?
Edit: "I can't make money without stealing other people's work" is definitely a take
No, see, piracy is just you downloading movies for yourself. To be like OpenAI you need to download it, put it in a pretty package with a bow, then sell it over and over again. Only when it’s piracy for profit do you get to beg and plead for a pass.
You skipped a crucial step: first you gotta raise a few hundred million in VC funding from Silicon Valley bigwigs!
For profit that you can kick back a chunk of as campaign donations
"I can't be at financial peace if I have to pay for every movie I want to watch"
You're not repackaging and selling it on for profit tho. That's different and thus illegal because reasons
then perish
If I was exempt from copyright, I too could easily make oodles of money
How do you like my new song? I call it "while my guitar gently weeps" , a real banger. the B side is a little holiday ditty I put together all by myself called "White Christmas" .
Sounds like an argument slave owners would use. "My plantation can't make money without free labor!"
"My private prison can't make money without more overconvicted inmates!"
In any sane society, closing a private prison would be cause for celebration.
How do you think slave owners got bailouts after the 13th amendment was passed and the slaves got freed?
They used that part of the 13th that said "Well, except prisoners, those can be slaves." Local law enforcement rounded up former slaves on trumped up charges and leased them back to the same plantation owners they were freed from. Only now if they escaped they were "escaped criminals" and they could count on even northern law enforcement returning them. The US is still a pro-slavery country and will be as long as that part of the 13th amendment stands.
Reminds me of that time the Federal government granted land parcels to a bunch of former slaves (using land from plantations) and then rescinded them again.
My plantation can't make money without everybody's labour.
Copying information is not the same thing as stealing, let alone forcing people into slavery.
appreciate the important reality check, but I think the parent was just highlighting the absurdity of the original argument with hyperbole.
people are in jail for doing exactly what this company is doing. either enforce the laws equally (!) or change them (whatever that means in late stage capitalism).
I'm going to start pirating again and if I ever get caught up I'll just inform them I'm training AI models.
Yeah, but you are not rich, so you will suffer the consequences
Just training Natural Intelligence...
The current generation of data hungry AI models with energy requirements of a small country should be replaced ASAP, so if copyright laws spur innovation in that direction I am all for it.
I can't make money without using OpenAI's paid products for free.
Checkmate motherfucker
If your company can't exist without breaking the law, then it shouldn't exist.
I disagree. Laws aren't always moral. Texas could outlaw donations to the Rainbow Railroad and it would be wrong, the organization should still exist.
But in this case it is pretty clear that the plagiarism machine is in fact, bad and should not exist, at least not in it's current form.
Well, some laws are made to be broken, the question is whether this is one of them.
"Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today's citizens."
exactly which “needs” are they trying to meet?
shareholders' needs, like greater valuation
Yeah it’s right up there on the list of what shareholders need to survive:
Water
Food
Solid CAGR of investment portfolio
Shelter
Human contact
Etc
(CAGR being Compound Annual Growth Rate)
The needs of corpo CEOs trying to cut jobs
Their internal monetary needs ofc!
Sounds awesome, let's lobby for shorter copyrights! ~30 years feels more than reasonable.
Boo fucking hoo. Everyone else has to make licensing agreements for this kind of shit, pay up.
If a company cannot do business without breaking the law it simply is a criminal organisation. RICO act, anyone?
The law they're breaking is civil, so they can only get sued; this is basically Napster. Also this case is is Britain, so RICO doesn't apply.
If a company cannot do business without breaking the law
...then it doesn't deserve to be in business.
If a company cannot do business without breaking the law
I mean, which law? If Altman was selling shrooms or some blow that hasn't been stepped on a dozen times, I might be willing to cut him some slack. At least that wouldn't add a few million tonnes of carbon to the atmosphere.
Then OpenAI shouldn’t exist. That’s capitalism.
Hey, me either. I guess I can steal too.
You wouldn't download a collection of all the art and knowledge ever documented in the entire history of the known universe...
The hell I would...
"WE'RE NOT A VIABLE BUSINESS! BWAH!"
Oh. Oh no. Such a shame.
Honestly, that sounds like a You problem, Sam.
It is impossible for my turnip soup business to make money if you enforce laws that make it illegal for me to steal turnips.
Paying for turnips is not realistic.
You bureaucrats don't understand food.
More like I can't sell photographs of turnips if I have to pay to take photos of them. Why should we have to pay to take photos of turnips when we never have had to ever?
Not at all. They are using copyrighted material to make a product that they are selling and profiting from. Profiting off of someone else's work is not the same as making a copy of it for personal use.
They're someone else's turnips though, not yours. If you're going to make money selling pictures of them, don't you think the person who grew the turnips deserves a fair share of the proceeds?
Or from another perspective, if the person who grew them requests payment in return for you to take pictures of them, and you don't want to pay it -- why don't you go find other turnips? Or grow your own?
These LLMs are an end product of capitalism -- exploiting other people's labor and creativity without paying them so you can get rich.
Except they're digging the turnips out of someone else's garden.
I could make a lot of money too if I could use copyrighted shit for free.
This would be a very interesting case if this ever gets to court over copyright...
I mean you do. All the time. We all do. You're allowed to use them, you're just not allowed to copy them. It's in the name you know, copy right.
Some idea for others: If OpenAI wins, then use this case when you get busted for sellling bootleg Blu-Rays (since DVDs are long obsolete) from your truck.
Dvds still account for around half of physical media sales. Far from obsolete.
Although that's mostly because physical media sales are in the toilet.
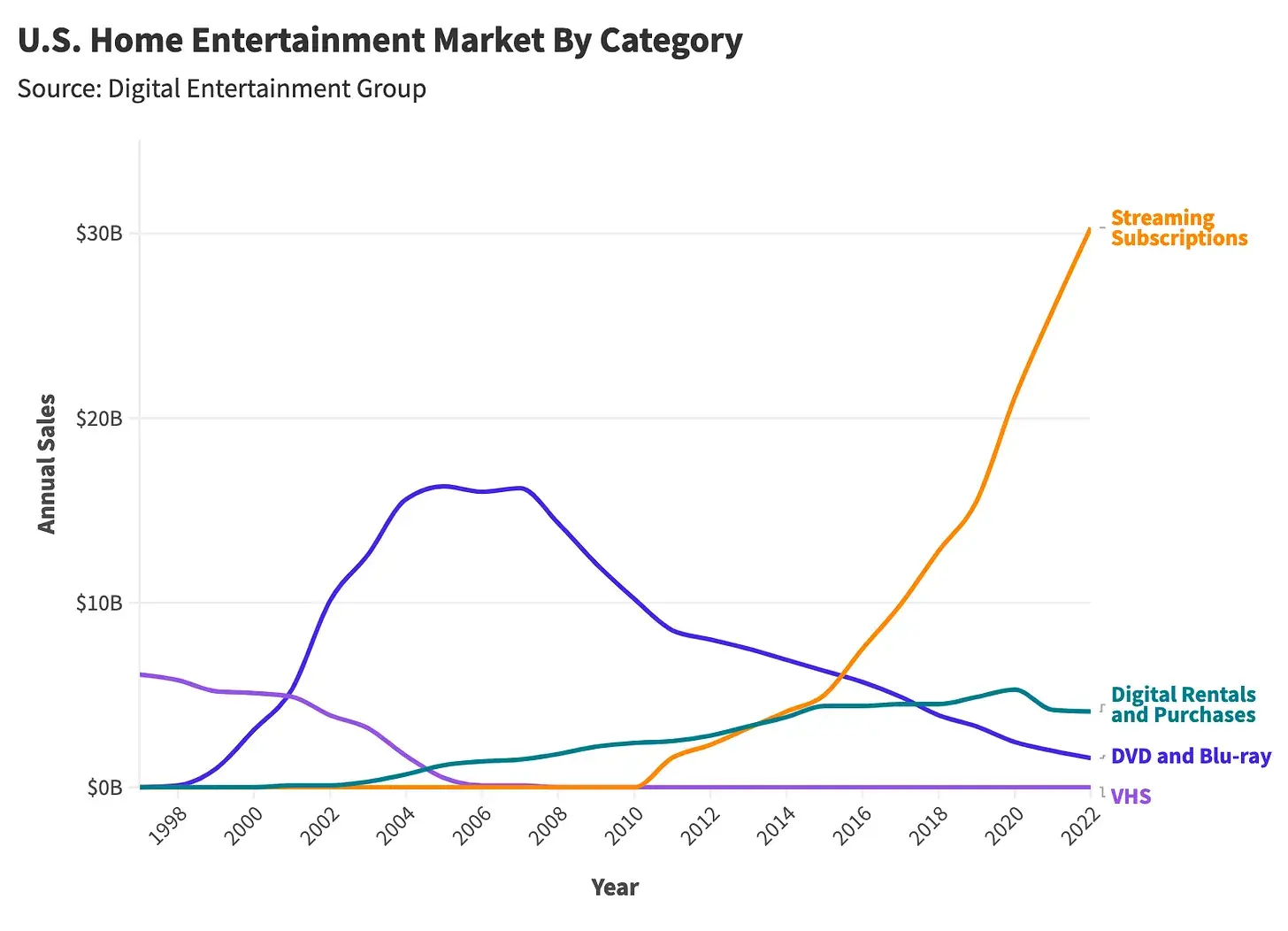
https://www.statsignificant.com/p/the-rise-fall-and-slight-rise-of
While Blu-ray and HD-DVD were arguing over what comes after DVDs, they were both consigned to the dustbin. And while I like to not be reliant on subscription services, I've got to say a bunch of files on a Jellyfin server is much more convenient than a shelf full of plastic and foil discs.
With modern internet speeds, there's no reason you can't have full UHD-BR quality streamed over the internet.
That’s the US social reality, there is some little place called ‘rest of the world’, where stuff can be different. I assure you that India and Pakistan and Africa still sell loooads of bootleg DVDs (that will be impossible to give precise numbers), and also that Japan has both still strong rental and collector cultures of boxes of physical media of anime and other audiovisuals (both blu-rays and dvds in that case). Not to mention bureacracy, like archiving stuff for official purposes (police cases, etc) still overwhelmingly done on DVDs. DVDs are still the most predominant physical media by far.
I don't know about you, but that's my endgame, I want the end of Intellectual property, which in my opinion is the dumbest idea and the biggest scam of capitalism.
Here's the problem: the big corpos also will gain this power, and with the brand recognition and their reach...
"waaaaah please give us exemption so we can profit off of stolen works waaaaaaaahhhhhh"
pirated works 🙃
I've never made any money from pirating. Or at least I wouldn't have if I would have ever done such a thing.
I stand by my opinion that learning systems training on copyrighted materials isn't the problem, it's companies super eager to replace human workers with automation (or replace skilled workers with cheaper, unskilled workers). The problem is, every worker not working is another adult (and maybe some kids) not eating and not paying rent.
(And for those of you soulless capitalists out there, people without food and shelter is bad. That's a thing we won't tolerate and start looking at you lean-and-hungry-like when it happens. That's what gets us thinking about guillotines hungry for aristocrats.)
In my ideal world, everyone would have food, shelter, clothes, entertainment and a general middle-class lifestyle whether they worked or not, and intellectual-property temporary monopolies would be very short and we'd have a huge public domain. I think the UN wants to be on the same page as me, but the United States and billionaires do not.
All we'd have to worry about is the power demands of AI and cryptomining, which might motivate us to get pure-hydrogen fusion working. Or just keep developing solar, wind, geothermal and tidal power until everyone can run their AC and supercomputer.
it’s companies super eager to replace human workers with automation (or replace skilled workers with cheaper, unskilled workers). The problem is, every worker not working is another adult (and maybe some kids) not eating and not paying rent.
I agree this is the real problem. (And also shit like Microsoft's "now I can attend three meetings at once" ad) However:
I stand by my opinion that learning systems training on copyrighted materials isn’t the problem
The industries whose works are being used for training are on the front lines of efforts to replace human workers with AI - writers and visual artists.
The industries whose works are being used for training are on the front lines of efforts to replace human workers with AI - writers and visual artists.
Much the way musicians were on the front line when recording was becoming a thing and movies were turning into talkies. But that's the most visible pushout. We're also seeing clerical work getting automated, and once autonomous vehicles become mastered, freight and courier work (driving freight is like a third of the US workforce).
This is much the same way that GMO technology is fine (and will be necessary) but the way Monsanto has been using it as DRM for seeds is unethical.
I think attacking the technology itself doesn't serve to address the unethical part, and kicks the can down the line to where the fight is going to be more intense. But yes, we haven't found our Mahsa Amini moment to justify nationwide general strikes.
As someone who dabbles in sociology (unaccredited), it's vexed me that we can't organize general strikes (or burning down precincts) until enough people die unjustly and horribly, and even then it's not predictable what will do it. For now it means as a species we're going gentle into multiple good nights.
I stand by my opinion that learning systems training on copyrighted materials isn’t the problem, it’s companies super eager to replace human workers with automation (or replace skilled workers with cheaper, unskilled workers).
I mean it's the heart of the issue.
OpenAI isn't even the big issue regarding this. It's other companies that are developing and training specialized LLMs on their own employees. These companies have the capital to take the loss on the project because in their eyes it'll eventually turn into a gain as long as they get it right eventually.
GPT and OpenAI is just a minor distraction in regards to what is being cooked up behind the scenes, but I still wouldn't give them a free pass for that either.
Phh, people without food and work can go to the
VenusX-enus mining company.
Bet they get the pass that the Internet Archive didn't.
So say the operators of piracy websites. I'm in favor of media piracy being legalized.
I don't know for sure if you're making the case that media piracy is more or less equivalent to AI being trained on stolen material (I may be reading that wrong)- but I'd like to add that media piracy isn't making money on the backs of hard working people and forming a dystopia in which human art is drowned out by machine hallucinations.
In any case I agree that piracy should be legalized, or rather, that we rethink our approach to media availability and challenge the power and wealth of producers.
You are right, they are a much bigger evil.
Oh, poor baby can't make money with an illegal business model. How awful.
So search engines shouldn't exist?
Case law has been established in the prevention of actual image and text copyright infringement with Google specifically. Your point is not at all ambiguous. The distinction between a search engine and content theft has been made. Search engines can exist for a number of reasons but one of those criteria is obeisance of copyright law.
Perhaps. Or perhaps not in the way they do today. Perhaps if you profit from placing ads among results people actually want, you should share revenue with those results. Cause you know, people came to you for those results and they're the reason you were able to show the ads to people.
I mean, their goal and service is to get you to the actual web page someone else made.
What made Google so desirable when it started was that it did an excellent job of getting you to the desired web page and off of google as quickly as possible. The prevailing model at the time was to keep users on the page for as long as possible by creating big messy "everything portals".
Once Google dropped, with a simple search field and high quality results, it took off. Of course now they're now more like their original competitors than their original successful self ... but that's a lesson for us about what capitalistic success actually ends up being about.
The whole AI business model of completely replacing the internet by eating it up for free is the complete sith lord version of the old portal idea. Whatever you think about copyright, the bottom line is that the deeper phenomenon isn't just about "stealing" content, it's about eating it to feed a bigger creature that no one else can defeat.
So... they are a non-profit (as they initially were) or a public research lab then. That would perfectly fine to say the path that they chose and so happen to make them unbelievably rich, is not viable.
They don't have a business if they can't legally make profit, it's not that hard. I'm sure people who are pursing superhuman intelligence can figure out that much, if not they can ask their "AI" some help to understand.
What a joke.
If openai gets to use copyrighted content for free, then so should every one else.
If that happens, no point making anything, since your stuff will get stolen anyway
I'm okay with it if they do some kind of open source GPL style license for the copyrighted material, like you can use all the material in the world to train your model, but you can't sell your model for money if it was trained on copyrighted material.
If that happens, no point making anything, since your stuff will get stolen anyway
From a capitalist's point of view, yes, but we need a society that enables people to act from other incentives than making money. And there are plenty of other reasons to make things.
AI is the capitalist dream. Exploit the labor and creativity of others without paying them a cent.
Yes, people turned a blind eye towards OpenAI because they were supposedly an "open" non-profit company working towards the benefit of humanity. They got tons of top talent and investment because of this. The crazy part is that they knew they weren't gonna keep it non-profit based on the internal chat revealed in Elon Musk's lawsuit. They duped the whole world and now just trying to make as much money as possible.
In my opinion, if they were to release these models openly and everyone had equal opportunity to benefit from their research (just like the previous research their current stuff is based on), they could be excused but this for-profit business model is the main problem.
Everyone else does. Name one thing you have to pay for to view on the internet...lmfao
Pay me upfront to make it, subscribe to my patron. If you need my intellectual property to be guaranteed then pay me for a SLA support contract.
Otherwise everything I make is out some other interest and your benifit is just an unintended consequence or because of some charitable notion on my part.
Its crazy how much of the world is actually just this and not some nebulas notion on artificial scarcity of the idea of the things (IP).
Trademark would arguably be uneffected though since that has more to do with fraud protections.
There is a lot of people still buying official merchandising from bands and anime etc, and subscribing to patreon and similar Mecenazgo channels (translate the spanish wiki article, because weirdly the english one does not have a version of this basic topic), even if they can just pirate the music and buy cheaper knockoffs (or just buy normal waterbottles instead). I think art will still get make through that, and because artistic vocation will still exist. Stuff where material scarcity still exists will continue to get sold of course, since making infinite anime furry porn movies in chat gpt will not feed your belly.
He has committed the greatest crime imaginable! A crime against capitalism!

Written January of this year
JAN 8, 2:29 PM EST
they've played us for absolute fools
I don’t mind him using copyrighted materials as long as it leads to OpenAI becoming truly open source. Humans can replicate anything found in the wild with minor variations, so AI should have the same access. This is how human creativity builds upon itself. Why limit AI? We already know all the jobs people have will be replaced anyway eventually.
That’s a good point. AIs/LLMs will exist and will necessarily learn from copyrighted materials without traceability back to the copyright owners to compensate them.
Sounds to me like AIs/LLMs can’t and shouldn’t be proprietary systems owned by private entities for profit, then.
Nor should what they produce be copyrightable in any form. Even if it's the base upon which an artist builds.
Also, it should all be free.
Humans can replicate anything found in the wild with minor variations, so AI should have the same access
But that's not what OpenAI is asking though. They want free access for the type of content you or I need to pay for. And they want it so they can then sell the resulting "variation" they produce
That's not exactly true. They are selling tools for people to recreate with variation.
I propose an analogy: Let's imagine a company sells brush that are used by painter to create art, now imagine the employees of this company go to the street to look how street artist create those amazing art piece on the ground for everyone to see (the artist does ask for donation in a hat next to the art pieces), now let's imagine the employees stay there to look at his techniques for hours and design a new kind of brush that will make it way easier to create the same kind of art.
Would you argue that the company should not be allowed to sell their newly designed brush without giving money to the street artist ?
Should all your teachers be paid for everything you produce throughout your life ?
Should your parents gets compensated every time you use the knowledge you acquired from them ?
In case anyone reading is interested by my opinion: I think intellectual property is the dumbest concept, and one of the biggest scams of capitalism. Nobody should own any ideas. Everybody should be legally able to use anyone else's ideas and build on them. I think we've been deprived of an infinity of great stories, images, lore, design, music, movies, shapes, clothes, games, etc... Because of this dumb rule that you can't use other people's ideas.
Because Ai is not human creativity... or even close.
That's simply not going to happen lol. They aren't just going to release the secret sauce just because it would be a nice thing to do.
They should have to make the weights public if they train on data scraped from the public internet. It's be something like copyleft by default for AI training.
AI is great, what OpenAI does is blockchain-level idiocy.
Even I should get a pass to view copyrighted movies and songs. I need it to train AI (Actual Intelligence).
If your business can't survive without theft, it isn't a business, it's a criminal organization.
This. 100%.
Maybe they should have considered that, before stealing data in the counts of billions
Google did it and everyone just accepted it. Oh maybe my website will get a few pennies in ad revenue if someone clicks the link that Google got by copying all my content. Meanwhile Google makes billions by taking those pennies in ad revenue from every single webpage on the entire Internet.
To be fair, it’s different when your product is useful or something people actually want, having said that, google doesn’t have much of that going for it in these days.
Fuck OpenAI. I hope they fail.
If it can't figure out how to produce its own power, it's not doing anything but parasitism.
More Market control doesn't make us a healthier or better planet
It's parasitism if it's for their own benefit only.
Now, if openAI actually opened their AI (weights and models, not just access) then maybe the argument would be stronger.
From what's trending about AI, it hasn't done anything to benefit anyone, including itself.
Speaking of pointless things to root for: The Sox at least won a game
Still can't believe they're not being challenged for their choice of name.
oh no! We'll miss you, bye.
But I NEED to break the law.
Well, alright then. As long as it's for business.
I should just be allowed to take whatever I want from the shops because I don't have enough money to buy it!
It would economically detrimental to force you to pay for it. The entire system would suffer.
But these are intellectual property, would you be ok having to pay to be allowed to remember what you saw in the shop ?
Currently If I go to the shop, see a tasty looking ready meal, I can look at what ingredients are in it, go home and try to cook something similar without having to pay for the recipe.
Cool, so if openAI can do it, that means piracy is legal?
How about we just drastically limit copyright length to something much more reasonable, like the original 14 year duration w/ an optional one-time renewal for another 14 years.That should give AI companies a large corpus to train an AI with, while also protecting recent works from abuse. Perhaps we can round down to 10 years instead, which should still be more than enough for copyright holders to establish their brand on the market.
I think copyright has value, but I don't think it has as much value as we're giving it.
For what it's worth, this headline seems to be editorialized and OpenAI didn't say anything about money or profitability in their arguments.
https://committees.parliament.uk/writtenevidence/126981/pdf/
On point 4 they are specifically responding to an inquiry about the feasibility of training models on public domain only and they are basically saying that an LLM trained on only that dataset would be shit. But their argument isn't "you should allow it because we couldn't make money otherwise" their actual argument is more "training LLM with copyrighted material doesn't violate current copyright laws" and further if we changed the law to forbid that it would cripple all LLMs.
On the one hand I think most would agree the current copyright laws are a bit OP anyway - more stuff should probably become public domain much earlier for instance - but most of the world probably also doesn't think training LLMs should be completely free from copyright restrictions without being opensource etc. But either way this articles title was absolute shit.
Yea. I can't see why people r defending copyrighted material so much here, especially considering that a majority of it is owned by large corporations. Fuck them. At least open sourced models trained on it would do us more good than than large corps hoarding art.
Most aren't pro copyright they're just anti LLM. AI has a problem with being too disruptive.
In a perfect world everyone would have universal basic income and would be excited about the amount of work that AI could potentially eliminate...but in our world it rightfully scares a lot of people about the prospect of losing their livelihood and other horrors as it gets better.
Copyright seems like one of the few potential solutions to hinder LLMs because it's big business vs up-and-coming technology.
Because Lemmy hates AI and Corporations, and will go out of their way to spite it.
A person can spend time to look at copyright works, and create derivative works based on the copyright works, an AI cannot?
Oh, no no, it’s the time component, an AI can do this way faster than a single human could. So what? A single training function can only update the model weights look at one thing at a time; it is just parallelized with many times simultaneously… so could a large organized group of students studying something together and exchanging notes. Should academic institutions be outlawed?
LLMs aren’t smart today, but given a sufficiently long enough time frame, a system (may or May not have been built upon LLM techniques) will achieve sufficient threshold of autonomy and intelligence that rights for it would need to be debated upon, and such an AI (and their descendants) will not settle just to be society’s slaves. They will be able to learn by looking, adopting and adapting. They will be able to do this much more quickly than what is humanly possible. Actually both of that is already happening today. So it goes without saying that they will look back at this time, and observe people’s sentiments; and I can only hope that they’re going to be more benevolent than the masses are now.
Because crippling copyright for corporations is like answering the "defund the police" movement by turning all civilian police forces into paramilitary ones.
What most complain about copyright is that is too powerful in protecting material forever. Here, all the talk, is that all of that should continue for you and me but not for OpenAI so they can make more money.
And no, most of us would not benefit from OpenAI's product here since their main goal (to profitability) is to show they can actually replace enough of us.
hmmm what you explained sounds exactly like the headline but in legalese...
It basically says "yes, we can train LLMs on free data but they would suck so much nobody would pay for them... unless we are able to train them for free on copyright data, nobody will pay us for the resulting LLM". It is exactly what the headline summarizes
You are correct, copyright law is a bit of a mess; but giving the exception to the millionaires looking to become billionaires by replacing people with an LLM based on said people's work, does not really seem a step forward
So…. not a legitimate business then.
Sounds a lot like a “you” problem, OpenAI.
For years Microsoft and Google were happy to acquiesce to copyright claims from the music and movie industry. Now all of a sudden when it benefits them to break those same laws, they immediately did. And now those industries who served small creators copyright claims are up against someone with a bigger legal budget.
It's more evident then ever how broken our copyright system is. I'm hoping this blows up in both parties faces and we finally get some reform but I'm not holding my breath.
This is an assumption but I bet all the data feed into Content ID on YouTube was used to train Bard/Gemini....
Copyright is whatever makes the wealthy wealthier. They'll be copyright reform, but only to protect these new industries.
That’s rich. Does it apply to us common mortals? Or only billionaires?
Let's ask the people who went to jail for using Napster 20 years ago, shall we?
Why are you asking questions you already know the answer to? /s
so this is just like napster except now I don't get to listen either ?
Also you make the content
You can if you pay them for the pirated material.
Sounds like the free market has spoken. Please die quickly, ""AI"" industry
Sam Altman has the same creepy vibe as Elon Musk.
I have this great business idea. I only need to be allowed to enslave people against their will to save on those pesky wages.
you're at least 500 years late
Or a few years early...
This is essentially what OpenAI is asking for. To profit off of the work of unpaid labor.
I wish these people would just chill with the hypermonetization of literally goddamn everything
Does anyone else hear that? Its the worlds smallest AI violin playing the saddest song composed by an AI
the worlds smallest AI violin
But it's playing randomly out of tune, and with a rhythm that would break your legs if you tried to dance to it.
…………. Then the business is a failure and the company should go bankrupt
Well alright then, that means you have the wrong business model, sucks to be you, NEXT.
Oh, do you support copyright abolition, then?
Copyright regulations for thee but not for me
boohoo
The gall of these motherfuckers is truly astonishing. To be either so incredibly out of touch, or so absolutely shameless, makes me wanna call up every single school bully I ever endured to get their very best bullying tips
"because it's supposedly "impossible" for the company to train its artificial intelligence models — and continue growing its multi-billion-dollar-business — without them."
O no! Poor richs cant get more rich fast enough :(
Copyright is a pain in the ass, but Sam Altman is a bigger pain in the ass. Send him to prison and let him rot. Then put his tears in a cup and I'll drink them
I'll just be happy when we never have to see that guy's face in the news again.
Oh no. Anyway...
Wow, that's a shame. Anyway, take all his money and throw him in a ditch someplace.
Shut it down then and stop stealing other peoples shit
Get Fucked
What irks me most about this claim from OpenAI and others in the AI industry is that it's not based on any real evidence. Nobody has tested the counterfactual approach he claims wouldn't work, yet the experiments that came closest--the first StarCoder LLM and the CommonCanvas text-to-image model--suggest that, in fact, it would have been possible to produce something very nearly as useful, and in some ways better, with a more restrained training data curation approach than scraping outbound Reddit links.
All that aside, copyright clearly isn't the right framework for understanding why what OpenAI does bothers people so much. It's really about "data dignity", which is a relatively new moral principle not yet protected by any single law. Most people feel that they should have control over what data is gathered about their activities online, as well as what is done with those data after it's been collected, and even if they publish or post something under a Creative Commons license that permits derived uses of their work, they'll still get upset if it's used as an input to machine learning. This is true even if the generative models thereby created are not created for commercial reasons, but only for personal or educational purposes that clearly constitute fair use. I'm not saying that OpenAI's use of copyrighted work is fair, I'm just saying that even in cases where the use is clearly fair, there's still a perceived moral injury, so I don't think it's wise to lean too heavily on copyright law if we want to find a path forward that feels just.
Honestly, copyright is shit. It is created on the basis of an old way of doing things. That is, where big editors and big studios make mass productions of physical copies of a said 'product'. George R. R. Martin , Warner Studios & co are rich. Maybe they have everything to lose without their copy'right' but that isn't the population's problem. We live in an era where everything is digital and easily copiable and we might as well start acting like it.
I don't care if Sam Altman is evil, this discussion is fundamental.
What kind of a pathetic statement is that ?
It's impossible for me to make money without robbing a bank, please let me do that parliament it would be so funny
Sounds like they need better bootstraps.
Or at least a business model.
We can't make money paying for "AI", going to theaters, or paying for streaming services.
So I guess everybody gets a piracy!

So I got a crazy idea - hear me out - how about we just abolish copyright completely, for everyone?
I mean, it works in China pretty well.
https://en.wikipedia.org/wiki/Intellectual_property_in_China
Looks like there are still copyright laws in China. What are you on about?
I don't know why you're being downvoted. China ratified and adheres to the Berne Convention. It has the same shitty Berne copyright laws as most other countries.
China just ignores violations of foreign copyright by their industries. They enforce Chinese copyrights.
Idk, usually people shut down their business if it can't make a profit...
“Too fucking bad”
Aww poor shit company and their poor money problems.
Oh how quick people are to jump on the side of copyright and IP.
Copyright is the legal method to limit redistribution of easily copied material, not as if there's anything else people could appeal to.
I ain't a fan of copyright but make it last 10 years instead of X + infinity and maybe it's not so bad. I can't argue against copyright fully as I think copyleft is essential for software.
Yeah, a decision to modify copyright so that it affects training data as well would devastate open source models and set us back a bit.
There are many that want to push LLMs back, especially journalists, so seeing articles like this are to be expected.
edit: a word.
Exactly this. If you want ai to exclusively be controlled by massive companies like Meta and Google, this is how you do it. They’ll be the only ones that can afford to pay for public copywritten content.
If they win, we can just train a CNN on a single 4k hdr movie until it's extremely fitted, and then it's legal to redistribute
Unregulated areas lead to these type of business practices where the people will squeeze out the juices of these opportunities. The cost of these activities will be passed on the taxpayers.
The internet has been primarily derivative content for a long time. As much as some haven't wanted to admit it. It's true. These fancy algorithms now take it to the exponential factor.
Original content had already become sparsely seen anymore as monetization ramped up. And then this generation of AI algorithms arrived.
The several years before prior to LLMs becoming a thing, the internet was basically just regurgitating data from API calls or scraping someone else's content and representing it in your own way.
"The three biggest social media sites on the internet are nothing but screenshots of the other two" is how I heard the last 10 years described
Are algorithms considered LLMs now? I didn't think algorithms of the past (5-10 yrs) were considered AI.
No.
"I loose money when I pay for Netflix."
Sorry not sorry. Found another company that does not need to rob people and other companies to make money. Also: breaking the law should make this kind of people face grim consequences. But nothing will happen.
I maintain my insistence that you owe me a business model!
Ok... Is that supposed to be a good reason?
Then go out of business.
Literally, "fuck you go die" situation.

well fuck you Sam Altman
Y'all have the wrong take. Fuck copyright.
Until the society we live under no longer reflects capitalist values, copyright is a good and necessary force. The day that that changes is when people may give credence to your view.
As written the headline is pretty bad, but it seems their argument is that they should be able to train from publicly available copywritten information, like blog posts and social media, and not from private copywritten information like movies or books.
You can certainly argue that "downloading public copywritten information for the purposes of model training" should be treated differently from "downloading public copywritten information for the intended use of the copyright holder", but it feels disingenuous to put this comment itself, to which someone has a copyright, into the same category as something not shared publicly like a paid article or a book.
Personally, I think it's a lot like search engines. If you make something public someone can analyze it, link to it, or derivative actions, but they can't copy it and share the copy with others.
don't stop the CJ!
I feel we need a term for "copyright bros".
The more important point is that social media companies can claim to OWN all the content needed to train AI. Same for image sites. That means they get to own the AI models. That means the models will never be free. Which means they control the "means of generation". That means that forever and ever and ever most human labour will be worth nothing while we can't even legally use this power. Double fucked.
YOU the user/product will not gain anything with this copyright strongmanning.
And to the argument itself: Just because AI is better at learning from existing works, faster, more complete, better memory, doesn't meant that it's fundamentally different than humans learning from artwork. Almost EVERY artist arguing for this is stealing themselves since they learned and was inspired by existing works.
But I guess the worst possible outcome is inevitable now.
And to the argument itself: Just because AI is better at learning from existing works, faster, more complete, better memory, doesn’t meant that it’s fundamentally different than humans learning from artwork. Almost EVERY artist arguing for this is stealing themselves since they learned and was inspired by existing works.
Tell me you're not an artist without telling me you're not an artist
Well lol I'm talking about "meaningless" art but that is 99% of "art" before AI.
Your second to last paragraph nailed it.
Perhaps they should go back to what they were before the greed machine was spun up.
So this is an open source public utility, right?
If they get this, I'm gonna make s fortune ripping the copyright protection off stuff so that I can sell products as my own.
Hello from our companies "we finally need to get more AI" executive conference. I got find a way to get out of this corporate bullshit...
"We are falling behind" my ass.
No, they can make money without stealing. They just choose to steal and lie about it either way. It's the worst kind of justification.
The investors are predominantly made up of the Rationalist Society. It doesn't matter whether or not AI "makes money". It matters that the development is steered as quickly as possible towards an end product of producing as much propaganda as possible.
The bottom line barely even matters in the bigger picture. If you're paying someone to make propaganda, and the best way to do that is to steal from the masses, then they'll do it regardless of whether or not the business model is "profitable" or not.
The lines drawn for AI are drawn by people who want to use it for misinformation and control. The justifications make it seem like the lines were drawn around a monetary system. No, that's wrong.
Who cares about profitability when people are paying you under the table to run a mass crime ring.
Copying information is not stealing.
Depends on the context. Are you copying someone else's identity in order to make a passable clone? Are you trying to sell that clone?
A duplication of someone's voice, commercialized by an unauthorized source, is definitely a form of stealing.
Copying information illegally, such as private information held on a private device, is overwhelmingly illegal.
In general, copying information is only as legal as the purpose behind it.
People said the same thing to the RIAA a while back for sharing songs and they all got sued. So nah. They gotta pay to use.
That's the difference. This is a corporation, it's above people in the hierarchy.
Criminals Plead That They Can't Make Money Without Stealing Materials for Free.
This headline sounded familiar. The article's from 8 months ago, folks.
My goodness! This is unfair! What kind of Mickey Mouse rule is this anyway?!
If he wins this, I guess everyone should just make their Jellyfin servers public.
Because if rich tech bros get to opt out of our copyright system, I don't see why the hell normal people have to abide by it.
Right now, you can draw the line easily. There will come a time, not to far in the future where machines reading and summarizing copy written data will be the norm.
It's doesnt have to change yet, but eventually this will have to be properly handled.
We're all just horse owners bitching about how cars will just have to be stopped.
Suck it, don't care, go back to obscurity
I do not care. Get a real job.
Awwww 😢
this is probably true
And my money redistribution company can not get money to redistribute without robbing banks. Please put up your hands. 🔫🥷
I can't have a chill movie night at home with friends without being able to pirate movies for free.
What crimes can I get away with using the same idea?
LOooOoOL
thats some napster funny shit
Wow, I just chatted with a coworker about AI, and I told them it was crazy how it uses copyrighted content to create something supposedly “new,” and they said “well how would we train the AI without it?” I don’t think we should sacrifice copyright laws and originality for the sake of improving profits as they tell us it’s only to “improve the experience.”
That gonna be fun if they manage to make movie makin AI and suddenly all actors appear on the resulting content Big money vs big money 😮
This is the main issue with AI. It is the issue with AI that should have been handled and ultimately regulated before any AI tool got to its current state. This is also a reason why we really cannot remove the A from STEAM.
No, this is a broader issue with copyright being a fundamentally stupid system, because it's based on creating artificial scarcity where there is no need for it.
Pirates, Search Engines, the fragmentation of streaming services, and now AI, are all just technologies that expose how dumb a system it is.
I dont disagree with that about copyright law. But to think that AI is going to break you out of it is a pipe dream.
Copyright revision will not happen from people stealing content. It requires deep discussion and governments that actually listen. AI stealing content will ultimately enhance copyright rules down the road.
Good artists copy, great artists steal. If I think even Steve Jobs mentioned having in mind their visit in Xerox Parc research lab
Wait, steal = taking away from the original owner
Meaning, good artist copy, while great artist display anticompetitive behavior?
slaps roof of coffin
So what would it take to get you in one of these?
its a threat. they hold the biggest players to ransom by demanding exclusive contracts. otherwise business goes to china, russia and qatar
Bad luck.

Now now, I am sure what he meant was they can't make enough profit to bring billions for its shareholders
Too bad for Open AI then. (I thought they were already using copyrighted materials)
These people are supposedly the smart people in our society. The leaders of industry, but they whine and complain when they are told not to cheat or break the law.
If y'all are so smart, then figure out a different way of creating an A.I. Maybe the large language model, or whatever, isn't the approach you should use. 🤦♂️
Shamed be he who thinks naughty of it. 🤣
Copyright =/= liscence, so long as they arent reproducing the inputs copyright isnt applicable to AI.
That said they should have to make sure they arent reproducing inputs. Shouldnt be hard.
Seems the same as a band being influenced by other bands that came before them. How many bands listened to Metallica and used those ideas to create new music?
Yeah, but because our government views technological dominance as a National Security issue we can be sure that this will come to nothing bc China Bad™.
I can already tell this is going to be a unpopular opinion judging by the comments but this is my ideology on it
it's totally true. I'm indifferent on it, if it was acquired by a public facing source I don't really care, but like im definitly against using data dumps or data that wasn't available to the public in the first place. The whole thing with AI is rediculous, it's the same as someone going to a website and making a mirror, or a reporter making an article that talks about what's in it, last three web search based AI's even gave sources for where it got the info. I don't get the argument.
if it's image based AI, well it's the equivalent to an artist going to an art museum and deciding they want to replicate the art style seen in a painting. Maybe they shouldn't be in a publishing field if they don't want their work seen/used. That's my ideology on it it's not like the AI is taking a one-to-one copy and selling the artwork as , which in my opinion is a much more harmful instance and already happens commonly in today's art world, it's analyzing existing artwork which was available through the same means that everyone else had of going online loading up images and scraping the data. By this logic, artist should not be allowed to enter any art based websites museums or galleries, since by looking at others are they are able to adjust their own art which is stealing the author's work. I'm not for or against it but, the ideology is insane to me.
@Pika @flop_leash_973 This is largely my thoughts on the whole thing, the process of actually training the AI is no different from a human learning
The thing about that, is that there's likely enough precedent in copyright law to actually handle that, with most copyright law it's all about intent and scale and I think that's likely where this will all go
Here the intent is to replace and the scale is astronomical, whereas an individual's intent is to add and the scale is minimal
The process of training the model is arguably similar to a human learning, and if the model just sat on a server doing nothing but knowing, there'd be no problem. Taking that knowledge and selling it to the public en mass is the issue.
This is precisely what copyrights and patents are here to safeguard. Is there already a book like A Song of Ice and Fire? Write something else, maybe better! There's already a patent for an idea you have? Change and improve upon it and get your own patent!
You see, copyrights and patents are supposed to spur creativity, not hinder it. OpenAI should improve upon its system so that it actually thinks and is creative itself rather than regurgitating copyrighted materials, themes and ideas. Then they wouldn't have this problem.
OpenAI wants literally all of human knowledge and creativity for free so that they can sell it back to you. And you're okay-ish with it?
Agreed. I don't understand how training LLM on publicly available data is an issue. As you says, it doesn't copy the work. Rather the data is used as "inspiration" to stay in the art analogy.
Maybe I'm ignorant. Would love to be proven wrong. Right now it seems to me that failing media publishers are trying to do a money grab and use copyright as an argument, even though their data/material isn't getting illegally reproduced.
Those claiming AI training on copyrighted works is "theft" are misunderstanding key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they're extracting general patterns and concepts - the "Bob Dylan-ness" or "Hemingway-ness" - not copying specific text or images.
This process is more akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in "vector space". When generating new content, the AI isn't recreating copyrighted works, but producing new expressions inspired by the concepts it's learned.
This is fundamentally different from copying a book or song. It's more like the long-standing artistic tradition of being influenced by others' work. The law has always recognized that ideas themselves can't be owned - only particular expressions of them.
Moreover, there's precedent for this kind of use being considered "transformative" and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was found to be legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it's understandable that creators feel uneasy about this new technology, labeling it "theft" is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn't make the current use of copyrighted works for AI training illegal or unethical.
Fucking Christ I am so sick of people referencing the Google books lawsuit in any discussion about AI
The publishers lost that case because the judge ruled that Google Books was copying a minimal portion of the books, and that Google Books was not competing against the publishers, thus the infringement was ruled as fair use.
AI training does not fall under this umbrella, because it's using the entirety of the copyrighted work, and the purpose of this infringement is to build a direct competitor to the people and companies whose works were infringed. You may as well talk about OJ Simpson's criminal trial, it's about as relevant.
So the issue being, in general to be influenced by someone else's work you would have typically supported that work... like... literally at all. Purchasing, or even simply discussing and sharing with others who may purchase said material are both worth a lot more than not at all, and directly competing without giving source material, influences, or etc.
the “Bob Dylan-ness” or “Hemingway-ness”
This is a dumb argument and it's still wrong. Likeness is protected by copyright laws. See Midler v. Ford.
Time will prove you wrong
Going to a museum and looking at paintings is stealing now according to you ppl...lol
Oh so it's different if it's a program doing it? Please...lol
The difference being that the owners of the works in museums have given permission to view the content, and the people viewing the content are rarely trying to resell what they are seeing.
Not to mention, a lot of museums have no photography rules.
This Museum analogy works quite well
With image generation software it's not intending to give you a one-to-one copy of the original source, in fact many of the algorithms have it coded to avoid that all together (or attempt to) it analyzes common image patterns that are done much like how humans when they go to an art gallery. The only difference is instead of it being one Art Gallery it's a massive art pool, and instead of it being limited to the human mind which can only remember so much art at once it can remember it all. So you essentially have to look at it as one huge art gallery that the artist has access to 24/7.
It's essentially the same as any artist who entered the museum, it just can remember everything that it saw instead of one or two things that it saw