Search
How do I give Jellyfin permanent access to an external drive?
I didn't like Kodi due to the unpleasant controls, especially on Android, so I decided to try out Jellyfin. It was really easy to get working, and I like it a lot more than Kodi, but I started to have problems after the first time restarting my computer.
I store my media on an external LUKS encrypted hard drive. Because of that, for some reason, Jellyfin's permission to access the drive go away after a reboot. That means something like chgrp -R jellyfin /media/username does work, but it stops working after I restart my computer and unlock the disk.
I tried modifying the /etc/fstab file without really knowing what I was doing, and almost bricked the system. Thank goodness I'm running an atomic distro (Fedora Silverblue), I was able to recover pretty quickly.
How do I give Jellyfin permanent access to my hard drive?
Solution:
- Install GNOME Disks
- Open GNOME Disks
- On the left, click on the drive storing your media
- Click "Unlock selected encrypted partition" (the padlock icon)
- Enter your password
- Click "Unlock"
- Select the LUKS partition
- Click "Additional partition options" (the gear icon)
- Click "Edit Encryption Options..."
- Enter your admin password
- Click "Authenticate"
- Disable "User Session Defaults"
- Select "Unlock at system startup"
- Enter the encryption password for your drive in the "Passphrase" field
- Click "Ok"
- Select the decrypted Ext4 partition
- Click "Additional partition options" (the gear icon)
- Click "Edit Mount Options..."
- Disable "User Session Defaults"
- Select "Mount at system startup"
- Click "Ok"
- Navigate to your Jellyfin Dashboard
- Go to "Libraries"
- Select "Add Media Library"
- When configuring the folder, navigate to
/mntand then select the UUID that points to your mounted hard drive
I've set up docker services behind nginx proxy manager so they're accessible with https, but the http services are still open. How do I close them?
I'm using a docker compose file, and I have everything running just fine, containers talking to each other as needed, NPM reverse proxying everything via a duckdns subdomain... everything's cool.
Problem is, I can still go to, for example, http://192.168.1.30:8080 and get the services without http.
I've tried commenting out the ports in the compose file, which should make them only available on the internal network, I thought. But when I do that, the containers can no longer connect to each other.
Any advice for me?
Edit:
Thanks for the quick & helpful suggestions!
While investigating bridge networks, I noticed a mention that containers could only find each other on the default container bridge by container name, which I did not know. I had tried 127.0.0.1, localhost, the external IP, hostnames, etc but not container names.
In the end, the solution was just to use container names when telling each container how to find the others. No need for creating bridge networks or any other shenanigans.
Thank you!
Nextcloud can't see config.php in new install directory
Update: Turned out I had like 3 versions of php and 2 versions of postgres all installed in different places and fighting like animals. Cleaned up the mess, fresh install of php and postgres, restored postgres data to the database and bobs your uncle. What a mess.
Thanks to everyone who commented. Your input is always so helpful.
----- Original Post -----
Hey everyone, it's me again. I'm now on NGINX, surprisingly simple, not here with a webserver issue today though, rather a nextcloud specific issue. I removed my last post about migrating from Apache to Caddy after multiple users pointed out security issues with what I was sharing, as well as suggesting caddy would be unable to meet my complex hosting needs. Thank you, if that was you.
During the NGINX setup which has gone shockingly smoothly I moved all of my site root directories from /usr/local/apache2/secure to /var/www/
Everything so far has moved over nicely... that is until nextcloud. It's showing an "Internal Server Error" when loading up. When I check the logs in nextcloud/data/nextcloud.log it informs me nextcloud can't find the config.php file and is still looking in the old apache webroot. I have googled relentlessly for about four hours now and everything I find is about people moving data directories which is completely irrelevant. Does anyone know how to get F*%KING nextcloud to realize that config.php is in /var/www/nextcloud/config where it belongs? I'm assuming nextcloud has an internal variable to know where it's own document root is but I can't seem to find it.
Thanks for any tips.
Cheers
nextcloud.log <- you can click me
Can't renew cert on a self-hosted lemmy instance D:
EDIT: Thanks everyone for your time and responses. To break as little as possible attempting to fix this I've opted to go with ZeroSSL's DNS process to acquire a new cert. I wish I could use this process for all of my certs as it was very quick and easy. Now I just have to figure out the error message lemmy is throwing about not being able to run scripts.
Thank you all for your time sincerely. I understand a lot more than I did last night.
-------- Original Post --------
As the title says I'm unable to renew a cert on a self-hosted lemmy instance. A friend of mine just passed away and he had his hands all up in this and had it working like magic. I'm not an idiot and have done a ton of the legwork to get our server running and working - but lemmy specifically required a bit of fadanglin' to get working correctly. Unfortunately he's not here to ask for help, so I'm turning to you guys. I haven't had a problem with any of my other software such as nextcloud or pixelfed but for some reason lemmy just refuses to cooperate. I'm using acme.sh to renew the cert because that's what my buddy was using when he had set this all up. I'm running apache2 on a bare metal ubuntu server.
Here's my httpd-ssl.conf:
https://pastebin.com/YehfTPNV
Here's some recent output from my acme.sh/acme.log:
https://pastebin.com/PESVVNg4
Here's the terminal read out and what I'm attempting to execute:
https://pastebin.com/jfHfiaE0
If you can make any suggestions at all on what I might be missing or what may be configured incorrectly I'd greatly appreciate a nudge in the right direction as I'm ripping my hair out.
Thank you kindly for your time.
Is it possible to mount a ZFS drive in OpenMediaVault?
Original Post:
I recently had a Proxmox node I was using as a NAS fail catastrophically. Not surprising as it was repurposed 12 year old desktop. I was able to salvage my data drive, but the boot drive was toast. Looks like the sata controller went out and fried the SSD I was using as the boot drive. This system was running TurnKey FileServer as a LXC with the media storage on a subvol on a ZFS storage pool.
My new system is based on OpenMediaVault and I'm am happy with it, but I'm hitting my head against a brick wall trying to get it to mount the ZFS drive from the old system. I tried installing ZFS using the instructions here as OMV is based on Debian but haven't had any luck so far.
Solved:
- Download and install OMV Extras
- OMV's web admin panel, go to System -> Plugins and install the Kernel Plugin
- Go to System -> Kernel and click the blue icon that says Proxmox (looks like a box with a down arrow as of Jan 2025) and install the latest Proxmox kernel from the drop down menu.
- Reboot
- Go back to the web panel, System -> Plugins and install the plugin
openmediavault-zfs. - Go to Storage -> zfs -> Pools and click on the blue icon Tools -> Import Pool. From here you can import all existing zfs pools or a single pool.
OPNSense accessible on WAN by default?
Solved : I was still on my local network instead of my LTE network, so I was accessing the global ip through the local network, and thus the access page.
Hello,
I am running OPNSense as my router for my ISP and my local network.
When I access my global ip, it lands me on the login page of my OPNSense router. Is that normal?
The only Firewall WAN Rule I added is the rule to enable my Wireguard instance (and I disabled it to test if that was the issue)
I was messing with the NAT Outbound for the Road Warrior setup as explained in the OPNSense Road Warrior tutorial, but that rule is also disabled.
I enabled OutboundDNS to override a local domain.
And I have a dynamic DNS to access my VPN with a FQDN instead of the ip directly.
But otherwise, I have the vanilla configuration. I disabled all of these rules I've created to make sure that they weren't the issue, and I can still access my OPNSense from the WAN interface.
So is that a normal default behaviour? If so, how can I disable the access to the OPNSense portal from the WAN and keep it from within one of my LAN/VLAN?
___
Thanks guys! I was finally able to self host my own raw-html "blog"
So, I've been trying to accomplish this for a while. First I posted asking for help getting started, then I posted about trying to open ports on my router. Now, I proudly post about being able to show the world (for the first time ever) my abysmal lack of css and html skills.
I would like to thank everyone in this community, specially to those who took the time to answer my n00b questions. If you'd like to see it, it will be available at: https://kazuchijou.com/
(Beware however, for you might cringe into oblivion and back.)
Since this website is hosted on my desktop computer, there will be some down-time here and then, however I'll leave it on for the next 48 hours (rip electricity bill) only for you guys to see. <3
---
Now, there are a couple of things that need addressing:
I set it up as a cloudflare tunnel and linked it to my domain. However, I still don't know any docker at all (despite using it for the tunnel), and the process was too incredibly and stupidly easy. I don't think I learned as much as I expected and I didn't feel challenged at all.
The original idea was to do some port forwarding. (This was foolish and a bit of a waste of time). Despite getting a "public-ip-address" from my ISP, I still was unable to open ports successfully. I kept getting the same error again and again. If you'd like to read my original post about port forwarding you may follow this link: "[Solved] ((lie)) Noob stuck on port-forwarding wile trying to host own raw-html website. Pls help".
While I know doing this represents a security risk, I still wanted to at least have a small success with port forwarding. I just wanted to have the raw-internet-connection experience, you know? like, the basics and such. And Cloudflare is holding my hand way too hard, I want to feel like I can shoot myself in the foot (without actually doing so)
But to be honest, I'm quite happy with the outcome. There are many other avenues I'd like to explore in the future, like setting up a reverse proxy with nginx or even darknet hosting (as sugested by another commentor).
I hope to keep learning and some day help another poor soul like myself in a similar situation. I thank you again guys, you're the best.
[TL;DR] This is the best and most helpful community ever! thx <3
Forward authentication with Authentik for Firefly3
*** For anyone stumbling on this post, and is as newbie as I am right now, forward auth doesn't work with FireflyIII.
I thought that forward auth was the same as a proxy, but in this case, it is the proxy that provides the x-authentik tags.
So for Firefly, set up Authentik as a proxy provider and not a forward auth.
I haven't figured out the rest yet, but at least, x-authentik-email is in my header now.
Good luck ***
Hello,
I am trying to setup Authentik to do a forward auth for Firefly3, using caddy. I am trying to learn External authentication so my knowledge is limited.
My setup is as follows.
By looking at the Firefly doc Firefly doc, I need to set
AUTHENTICATION_GUARD=remote_user_guard
AUTHENTICATION_GUARD_HEADER=HTTP_X_AUTHENTIK_EMAIL in my .env file. I used the base .env file provided by Firefly and modified only these two lines
Then, in my Authentik, I made a forward auth for a single application for firefly. This part seem to work because the redirection is made. The external host is my Firefly ip address.
Then from the example provided in the Authentik provider, I created my caddy file on the Firefly container to redirect port 80 to my custom port 9080.
``` :80 { # directive execution order is only as stated if enclosed with route. route { # always forward outpost path to actual outpost reverse_proxy /outpost.goauthentik.io/* http://10.0.1.7:9080
# forward authentication to outpost forward_auth http://10.0.1.7:9080 { uri /outpost.goauthentik.io/auth/caddy
# capitalization of the headers is important, otherwise they will be empty copy_headers X-Authentik-Username X-Authentik-Groups X-Authentik-Email X-Authentik-Name X-Authentik-Uid X-Authentik-Jwt X-Authentik-Me>
# optional, in this config trust all private ranges, should probably be set to the outposts IP trusted_proxies private_ranges }
} } ```
EDIT : The IP address of Firefly is 10.0.1.8
When I try to go on my Firefly app, the Authentik redirection is made and it tries to connect to the Firefly webpage,but I either get unable to connect when I try the https, or Looks like there’s a problem with this site when I try to connect with http.
I see that the connection is refused in both case.
I made sure that my email on my account on firefly matches the email from the Authentik user.
I tried googling my problem to no avail and the Firefly documentation is pretty scarce.
Any help would be welcome.
Noob stuck on port-forwarding wile trying to host own raw-html website. Pls help
Edit: Solution
Yeah, thanks to u/[email protected] I contacted my ISP and found out that in fact they were blocking my port forwarding capabilities. I gave them a call and I had to pay for a public IP address plan and now it's just a matter of testing again. Thank you very much to everyone involved. I love you. It was Megacable by the way. If anyone from my country ever encounters the same problem I hope this post is useful to you.
Here's the original post:
Hey!
Ok, so I'm trying to figure this internet thing out. I may be stupid, but I want to learn.
So, what I'm essentially doing is trying to host my own raw html website on my own hardware and get it out to the internet for everyone to see (temporarily of course, I don't want to get in trouble with hackers and bots) I just want to cross that out of my bucket list.
What I've done so far:
- I set up a qemu/kvm virtual machine with debian as my server
- I configured a bridge so that it's available to my local network
- I got my raw html document
- I'm serving it locally with nginx
- I tried to set up port forwarding (I get stuck here)
Right now everyone in my home can see my ugly website if they go to 192.168.1.114:8080 (since I'm serving it through port 8080).
However, I want to be able to go outside (I'm testing it with my mobile network using mobile data) to see my website.
I've configured port forwarding on my ZTE router (ISP-issued) with the following parameters:
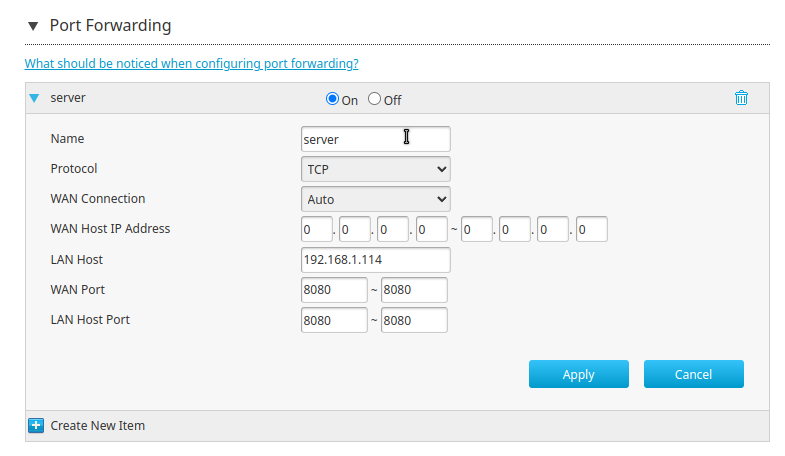{kind=link}
But now, if I search for my public IP address on my phone I don't get anything. Even if I go to my.public.ip.address:8080 (did you think I was gon-give you my public ip?)
I don't get anything. I've tried ping and curl. ping doesn´t even transmit the packages, curl says "Could not connect to server".
So, If you guys would be so kind as to point me in the right direction, I pose the following questions :
- How do I even diagnose this?
- What am I missing?
- Am I being too stupid?
- What do I do now?
(Here's a preview of my ugly website)
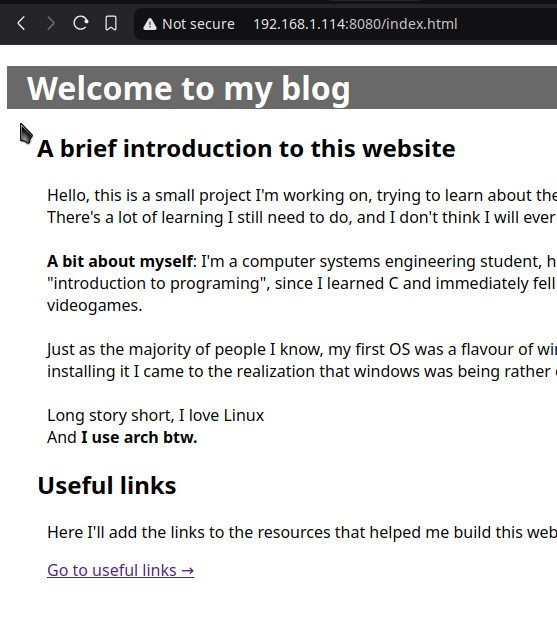{kind=link}
I also own a domain (with cloudflare) so, next step is getting that set-up with a DNS or something.
Thank youuuuuuu <3
Help Running Scrutiny
Hello All,
I am trying to run scrutiny via docker compose and I am running into an issue where nothing shows up on the wub UI. If anyone here has this working would love some ideas on what the issue could be.
as per there trouble shooting for this I followed those steps and here is the output
$ smartctl --scan /dev/sda -d scsi # /dev/sda, SCSI device /dev/sdb -d sat # /dev/sdb [SAT], ATA device /dev/nvme0 -d nvme # /dev/nvme0, NVMe device
docker run -it --rm \ -v /run/udev:/run/udev:ro \ --cap-add SYS_RAWIO \ --device=/dev/sda \ --device=/dev/sdb \ ghcr.io/analogj/scrutiny:master-collector smartctl --scan /dev/sda -d scsi # /dev/sda, SCSI device /dev/sdb -d sat # /dev/sdb [SAT], ATA device
So I think I am imputing the devices correctly.
I only really changed the port number for the web UI to 8090 from 8080 in there example as 8080 is taken. compose file ``` services: influxdb: image: influxdb:2.2 ports: - '8086:8086' volumes: - './influxdb:/var/lib/influxdb2' healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8086/health"] interval: 5s timeout: 10s retries: 20
web: image: 'ghcr.io/analogj/scrutiny:master-web' ports: - '8090:8090' volumes: - './config:/opt/scrutiny/config' environment: SCRUTINY_WEB_INFLUXDB_HOST: 'influxdb' depends_on: influxdb: condition: service_healthy healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8090/api/health"] interval: 5s timeout: 10s retries: 20 start_period: 10s
collector: image: 'ghcr.io/analogj/scrutiny:master-collector' cap_add: - SYS_RAWIO volumes: - '/run/udev:/run/udev:ro' environment: COLLECTOR_API_ENDPOINT: 'http://web:8090/' COLLECTOR_HOST_ID: 'scrutiny-collector-hostname' depends_on: web: condition: service_healthy devices: - "/dev/sda" - "/dev/sdb" ``` everything appears to start and work and no errors in the terminal.
Thanks for the help.
How to change qBittorrent admin password in docker-container?
I'm currently trying to spin up a new server stack including qBittorrent. when I launch the web UI, it asks for a login on first launch. According to the documentation, the default user id admin and the default password is adminadmin.
Solved:
For qBittorrent ≥ v4.1, a randomly generated password is created at startup on the initial run of the program. After starting the container, enter the following into a terminal:
docker logs qbittorrent or sudo docker logs qbittorrent (if you do not have access to the container)
The command should return:
******** Information ******** To control qBittorrent, access the WebUI at: http://localhost:5080 The WebUI administrator username is: admin The WebUI administrator password was not set. A temporary password is provided for this session: G9yw3qSby You should set your own password in program preferences.
Use this password to login for this session. Then create a new password by opening http://{localhost}:5080 and navigate the menus to -> Tools -> Options -> WebUI ->Change current password. Don't forget to save.
Chaining routers and GUA IPv6 addresses
Hey fellow self-hosting lemmoids
Disclaimer: not at all a network specialist
I'm currently setting up a new home server in a network where I'm given GUA IPv6 addresses in a 64 bit subnet (which means, if I understand correctly, that I can set up many devices in my network that are accessible via a fixed IP to the oustide world). Everything works so far, my services are reachable.
Now my problem is, that I need to use the router provided by my ISP, and it's - big surprise here - crap. The biggest concern for me is that I don't have fine-grained control over firewall rules. I can only open ports in groups (e.g. "Web", "All other ports") and I can only do this network-wide and not for specific IPs.
I'm thinking about getting a second router with a better IPv6 firewall and only use the ISP router as a "modem". Now I'm not sure how things would play out regarding my GUA addresses. Could a potential second router also assign addresses to devices in that globally routable space directly? Or would I need some sort of NAT? I've seen some modern routers with the capability of "pass-through" IPv6 address allocation, but I'm unsure if the firewall of the router would still work in such a configuration.
In IPv4 I used to have a similar setup, where router 1 would just forward all packets for some ports to router 2, which then would decide which device should receive them.
Has any of you experience with a similar setup? And if so, could you even recommend a router?
Many thanks!
---
Edit: I was able to achieve what I wanted by using OpenWrt and their IPv6 relay mode. Now my ISP router handles all IPv6 addresses directly, but I'm still able to filter the packets using the OpenWrt firewall. For IPv4 I didn't figure out how to, at the same time, use the ISP's DHCP server, so I just went with double NAT. Everything works like a charm. Thank you guys for pointing me in the right direction.
How do I redirect to a /path with Nginx Proxy Manager?
Hi folks,
Just set up Nginx Proxy Manager + Pihole and a new domain with Porkbun. All is working and I have all my services service.mydomain.com, however some services such as pihole seem to be strictly reachable with /admin at the end. This means with my current setup it only directs me to pihole.mydomain.com which leads to a 403 Forbidden.
This is what I have tried, but with no prevail. Not really getting the hang of this so would really appriciate a pinpoint on this :)
{kind=link}
Randomly getting ECH errors on self-hosted services.
In the last couple of weeks, I've started getting this error ~1/5 times when I try to open one of my own locally hosted services.
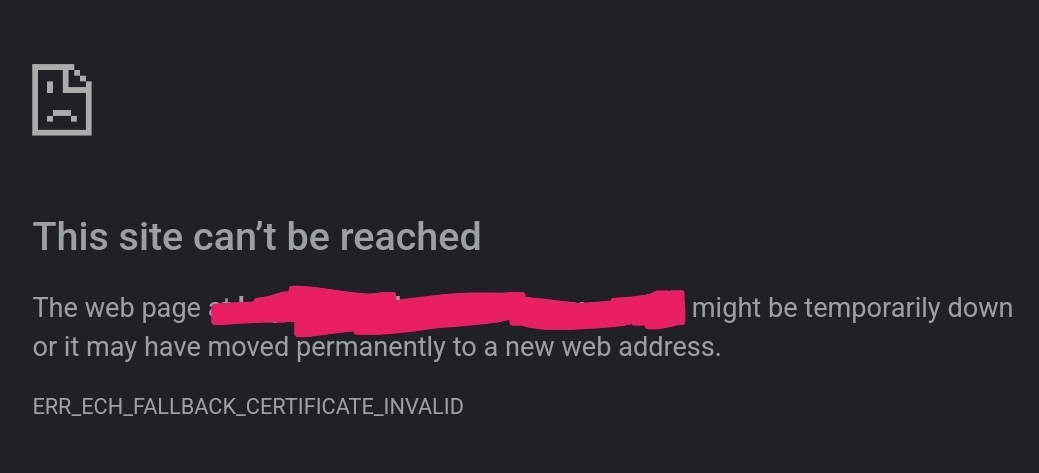{kind=link}
I've never used ECH, and have always explicitly restricted nginx to TLS1.2 which doesn't support it. Why am I suddenly getting this, why is it randomly erroring, then working just fine again 2min later, and how can I prevent it altogether? Is anyone else experiencing this?
I'm primarily noticing it with Ombi. I'm also mainly using Chrome Android for this. But, checking just now; DuckDuckGo loads the page just fine everytime, and Firefox is flat out refusing to load it at all.
! Firefox refuses to show the cert it claims is invalid, and 'accept and continue' just re-loads this error page. Chrome will show the cert; and it's the correct, valid cert from LE.
{kind=link}
There's 20+ services going through the same nginx proxy, all using the same wildcard cert and identical ssl configurations; but Ombi is the only one suddenly giving me this issue regularly.
The vast majority of my services are accessed via lan/vpn; I don't need or want ECH, though I'd like to keep a basic https setup at least.
Solution: replace local A/AAAA records with a CNAME record pointing to a local only domain with its own local A/AAAA records. See below comments for clarification.
Missing /etc/systemd/resolved.conf file
Solution: I just had to create the file
I wanted to install Pi-Hole on my server and noticed that port 53 is already in use by something.
Apparently it is in use by systemd-resolved:
~$ sudo lsof -i -P -n | grep LISTEN [...] systemd-r 799 systemd-resolve 18u IPv4 7018 0t0 TCP 127.0.0.53:53 (LISTEN) systemd-r 799 systemd-resolve 20u IPv4 7020 0t0 TCP 127.0.0.54:53 (LISTEN) [...]
And the solution should be to edit /etc/systemd/resolved.conf by changing #DNSStubListener=yes to DNSStubListener=no according to this post I found. But the /etc/systemd/resolved.conf doesn't exist on my server.
I've tried sudo dnf install /etc/systemd/resolved.conf which did nothing other than telling me that systemd-resolved is already installed of course. Rebooting also didn't work. I don't know what else I could try.
I'm running Fedora Server.
Is there another way to stop systemd-resolved from listening on port 53? If not how do I fix my missing .conf file?
Having difficulty visiting an mTLS-authenticated website from GrapheneOS
I host a website that uses mTLS for authentication. I created a client cert and installed it in Firefox on Linux, and when I visit the site for the first time, Firefox asks me to choose my cert and then I'm able to visit the site (and every subsequent visit to the site is successful without having to select the cert each time). This is all good.
But when I install that client cert into GrapheneOS (settings -> encryption & credentials -> install a certificate -> vpn & app user certificate), no browser app seems to recognize that it exists at all. Visiting the website from Vanadium, Fennec, or Mull browsers all return "ERR_BAD_SSL_CLIENT_AUTH_CERT" errors.
Does anyone have experience successfully using an mTLS cert in GrapheneOS?
Weird (to me) networking issue - can you help?
I have two subnets and am experiencing some pretty weird (to me) behaviour - could you help me understand what's going on?
----
Scenario 1
PC: 192.168.11.101/24 Server: 192.168.10.102/24, 192.168.11.102/24
From my PC I can connect to .11.102, but not to .10.102:
bash ping -c 10 192.168.11.102 # works fine ping -c 10 192.168.10.102 # 100% packet loss
----
Scenario 2
Now, if I disable .11.102 on the server (ip link set <dev> down) so that it only has an ip on the .10 subnet, the previously failing ping works fine.
PC: 192.168.11.101/24 Server: 192.168.10.102/24
From my PC:
bash ping -c 10 192.168.10.102 # now works fine
This is baffling to me... any idea why it might be?
----
Here's some additional information:
-
The two subnets are on different vlans (.10/24 is untagged and .11/24 is tagged 11).
-
The PC and Server are connected to the same managed switch, which however does nothing "strange" (it just leaves tags as they are on all ports).
-
The router is connected to the aformentioned switch and set to forward packets between the two subnets (I'm pretty sure how I've configured it so, plus IIUC the second scenario ping wouldn't work without forwarding).
-
The router also has the same vlan setup, and I can ping both .10.1 and .11.1 with no issue in both scenarios 1 and 2.
-
In case it may matter, machine 1 has the following routes, setup by networkmanager from dhcp:
default via 192.168.11.1 dev eth1 proto dhcp src 192.168.11.101 metric 410 192.168.11.0/24 dev eth1 proto kernel scope link src 192.168.11.101 metric 410
- In case it may matter, Machine 2 uses systemd-networkd and the routes generated from DHCP are slightly different (after dropping the .11.102 address for scenario 2, of course the relevant routes disappear):
default via 192.168.10.1 dev eth0 proto dhcp src 192.168.10.102 metric 100 192.168.10.0/24 dev eth0 proto kernel scope link src 192.168.10.102 metric 100 192.168.10.1 dev eth0 proto dhcp scope link src 192.168.10.102 metric 100 default via 192.168.11.1 dev eth1 proto dhcp src 192.168.11.102 metric 101 192.168.11.0/24 dev eth1 proto kernel scope link src 192.168.11.102 metric 101 192.168.11.1 dev eth1 proto dhcp scope link src 192.168.11.102 metric 101
----
solution
(please do comment if something here is wrong or needs clarifications - hopefully someone will find this discussion in the future and find it useful)
In scenario 1, packets from the PC to the server are routed through .11.1.
Since the server also has an .11/24 address, packets from the server to the PC (including replies) are not routed and instead just sent directly over ethernet.
Since the PC does not expect replies from a different machine that the one it contacted, they are discarded on arrival.
The solution to this (if one still thinks the whole thing is a good idea), is to route traffic originating from the server and directed to .11/24 via the router.
This could be accomplished with ip route del 192.168.11.0/24, which would however break connectivity with .11/24 adresses (similar reason as above: incoming traffic would not be routed but replies would)...
The more general solution (which, IDK, may still have drawbacks?) is to setup a secondary routing table:
bash echo 50 mytable >> /etc/iproute2/rt_tables # this defines the routing table # (see "ip rule" and "ip route show table <table>") ip rule add from 192.168.10/24 iif lo table mytable priority 1 # "iff lo" selects only # packets originating # from the machine itself ip route add default via 192.168.10.1 dev eth0 table mytable # "dev eth0" is the interface # with the .10/24 address, # and might be superfluous
Now, in my mind, that should break connectivity with .10/24 addresses just like ip route del above, but in practice it does not seem to (if I remember I'll come back and explain why after studying some more)
New Network Stack with an Unknown Issue..?
Update: It was DNS... its always DNS...
Hello there! I'm in a bit of a pickle.. I've recently bought the full budget Tp-link omada stack for my homelab. I got the following devices in my stack:
- ER605 Router
- OC200 Controller
- SG2008P PoE Switch
- EAP610 Wireless AP
- EAP625 Wireless AP (getting soon)
I've set it all up and it was working fine for the first few days of using it. However, last few days it's been working very much on and off randomly(?) . Basically devices will state they are connected to WiFi/Ethernet, but they are not actually getting it. (As seen in the picture). This is happening with our phones(Pixel7+S23U) and my server(NAS:Unraid), have not noticed any problems on our desktop PCs. So it is happening on both wired and wireless, as my server and desktop PC is connected to the switch.
I haven't done many configurations in the omada software yet, but am assuming it's something I have done that causes this... Would greatly appreciate any advice to solve/troubleshoot this!
Need help routing Wireguard container traffic through Gluetun container
The solution has been found, see the "Solution" section for the full write up and config files.
Initial Question
What I'm looking to do is to route WAN traffic from my personal wireguard server through a gluetun container. So that I can connect a client my personal wireguard server and have my traffic still go through the gluetun VPN as follows:
client <--> wireguard container <--> gluetun container <--> WAN
I've managed to set both the wireguard and gluetun container up in a docker-compose file and made sure they both work independently (I can connect a client the the wireguard container and the gluetun container is successfully connecting to my paid VPN for WAN access). However, I cannot get route traffic from the wireguard container through the gluetun container.
Since I've managed to set both up independently I don't believe that there is an issue with the docker-compose file I used for setup. What I believe to be the issue is either the routing rules in my wireguard container, or the firewall rules on the gluetun container.
I tried following this linuxserver.io guide to get the following wg0.conf template for my wireguard container:
```
[Interface]
Address = ${INTERFACE}.1
ListenPort = 51820
PrivateKey = $(cat /config/server/privatekey-server)
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -A FORWARD -o %i -j ACCEPT; iptables -t nat -A POSTROUTING -o eth+ -j MASQUERADE
Adds fwmark 51820 to any packet traveling through interface wg0
PostUp = wg set wg0 fwmark 51820
If a packet is not marked with fwmark 51820 (not coming through the wg connection) it will be routed to the table "51820".
PostUp = ip -4 rule add not fwmark 51820 table 51820
Creates a table ("51820") which routes all traffic through the gluetun container
PostUp = ip -4 route add 0.0.0.0/0 via 172.22.0.100
If the traffic is destined for the subnet 192.168.1.0/24 (internal) send it through the default gateway.
PostUp = ip -4 route add 192.168.1.0/24 via 172.22.0.1
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -D FORWARD -o %i -j ACCEPT; iptables -t nat -D POSTROUTING -o eth+ -j MASQUERADE
Along with the default firewall rules of the gluetun container
Chain INPUT (policy DROP 13 packets, 1062 bytes)
pkts bytes target prot opt in out source destination
15170 1115K ACCEPT 0 -- lo * 0.0.0.0/0 0.0.0.0/0
14403 12M ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
1 60 ACCEPT 0 -- eth0 * 0.0.0.0/0 172.22.0.0/24
Chain FORWARD (policy DROP 4880 packets, 396K bytes) pkts bytes target prot opt in out source destination
Chain OUTPUT (policy DROP 360 packets, 25560 bytes) pkts bytes target prot opt in out source destination 15170 1115K ACCEPT 0 -- * lo 0.0.0.0/0 0.0.0.0/0 12716 1320K ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 0 0 ACCEPT 0 -- * eth0 172.22.0.100 172.22.0.0/24 1 176 ACCEPT 17 -- * eth0 0.0.0.0/0 68.235.48.107 udp dpt:1637 1349 81068 ACCEPT 0 -- * tun0 0.0.0.0/0 0.0.0.0/0 ``` When I run the wireguard container with this configuration I can successfully connect my client however I cannot connect to any website, or ping any IP.
During my debugging process I ran tcpdump on the docker network both containers are in which showed me that my client is successfully sending packets to the wireguard container, but that no packets were sent from my wireguard container to the gluetun container. The closest I got to this was the following line:
17:27:38.871259 IP 10.13.13.1.domain > 10.13.13.2.41280: 42269 ServFail- 0/0/0 (28)
Which I believe is telling me that the wireguard server is trying, and failing, to send packets back to the client.
I also checked the firewall rules of the gluetun container and got the following results: ``` Chain INPUT (policy DROP 13 packets, 1062 bytes) pkts bytes target prot opt in out source destination 18732 1376K ACCEPT 0 -- lo * 0.0.0.0/0 0.0.0.0/0 16056 12M ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 1 60 ACCEPT 0 -- eth0 * 0.0.0.0/0 172.22.0.0/24
Chain FORWARD (policy DROP 5386 packets, 458K bytes) pkts bytes target prot opt in out source destination
Chain OUTPUT (policy DROP 360 packets, 25560 bytes) pkts bytes target prot opt in out source destination 18732 1376K ACCEPT 0 -- * lo 0.0.0.0/0 0.0.0.0/0 14929 1527K ACCEPT 0 -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 0 0 ACCEPT 0 -- * eth0 172.22.0.100 172.22.0.0/24 1 176 ACCEPT 17 -- * eth0 0.0.0.0/0 68.235.48.107 udp dpt:1637 1660 99728 ACCEPT 0 -- * tun0 0.0.0.0/0 0.0.0.0/0 ``` Which shows that the firewall for the gluetun container is dropping all FORWARD traffic which (as I understand it) is the sort of traffic I'm trying to set up. What is odd is that I don't see any of those packets in the tcpdump of the docker network.
Has anyone successfully set this up or have any indication on what I should try next? At this point any ideas would be helpful, whether that be more debugging steps or recommendations for routing/firewall rules.
While there have been similar posts on this topic (Here and Here) the responses on both did not really help me.
---
Solution
Docker Compose Setup
My final working setup uses the following docker-compose file:
networks: default: ipam: config: - subnet: 172.22.0.0/24 services: gluetun_vpn: image: qmcgaw/gluetun:latest container_name: gluetun_vpn cap_add: - NET_ADMIN # Required environment: - VPN_TYPE=wireguard # I tested this with a wireguard setup # Setup Gluetun depending on your provider. volumes: - {docker config path}/gluetun_vpn/conf:/gluetun - {docker config path}/gluetun_vpn/firewall:/iptables sysctls: # Disables ipv6 - net.ipv6.conf.all.disable_ipv6=1 restart: unless-stopped networks: default: ipv4_address: 172.22.0.100 wireguard_server: image: lscr.io/linuxserver/wireguard:latest container_name: wg_server cap_add: - NET_ADMIN environment: - TZ=America/Detroit - PEERS=1 - SERVERPORT=3697 # Optional - PEERDNS=172.22.0.100 # Set this as the Docker network IP of the gluetun container to use your vpn's dns resolver ports: - 3697:51820/udp # Optional volumes: - {docker config path}/wg_server/conf:/config sysctls: - net.ipv4.conf.all.src_valid_mark=1 networks: default: ipv4_address: 172.22.0.2 restart: unless-stopped
Once you get both docker containers working you still need to edit some configuration files.
Wireguard Server Setup
After the wireguard container setup you need to edit {docker config path}/wg_server/conf/templates/server.conf to the following:
``` [Interface] Address = ${INTERFACE}.1 ListenPort = 51820 PrivateKey = $(cat /config/server/privatekey-server)
Default from the wg container
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -A FORWARD -o %i -j ACCEPT; iptables -t nat -A POSTROUTING -o eth+ -j MASQUERADE
Add this section
Adds fwmark 51820 to any packet traveling through interface wg0
PostUp = wg set wg0 fwmark 51820
If a packet is not marked with fwmark 51820 (not coming through the wg connection) it will be routed to the table "51820".
PostUp = ip -4 rule add not fwmark 51820 table 51820 PostUp = ip -4 rule add table main suppress_prefixlength 0
Creates a table ("51820") which routes all traffic through the vpn container
PostUp = ip -4 route add 0.0.0.0/0 via 172.22.0.100 table 51820
If the traffic is destined for the subnet 192.168.1.0/24 (internal) send it through the default gateway.
PostUp = ip -4 route add 192.168.1.0/24 via 172.22.0.1
Default from the wg container
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -D FORWARD -o %i -j ACCEPT; iptables -t nat -D POSTROUTING -o eth+ -j MASQUERADE ```
The above config is a slightly modified setup from this linuxserver.io tutorial
Gluetun Setup
If you've setup your gluetun container properly the only thing you have to do is create {docker config path}/gluetun_vpn/firewall/post-rules.txt containing the following:
iptables -t nat -A POSTROUTING -o tun+ -j MASQUERADE iptables -t filter -A FORWARD -d 172.22.0.2 -j ACCEPT iptables -t filter -A FORWARD -s 172.22.0.2 -j ACCEPT
These commands should be automatically run once you restart the gluetun container. You can test the setup by running iptables-legacy -vL -t filter from within the gluetun container. Your output should look like:
```
Chain INPUT (policy DROP 7 packets, 444 bytes)
pkts bytes target prot opt in out source destination
27512 2021K ACCEPT all -- lo any anywhere anywhere
43257 24M ACCEPT all -- any any anywhere anywhere ctstate RELATED,ESTABLISHED
291 28191 ACCEPT all -- eth0 any anywhere 172.22.0.0/24
These are the important rules
Chain FORWARD (policy DROP 12276 packets, 2476K bytes) pkts bytes target prot opt in out source destination 17202 8839K ACCEPT all -- any any anywhere 172.22.0.2 26704 5270K ACCEPT all -- any any 172.22.0.2 anywhere
Chain OUTPUT (policy DROP 42 packets, 2982 bytes) pkts bytes target prot opt in out source destination 27512 2021K ACCEPT all -- any lo anywhere anywhere 53625 9796K ACCEPT all -- any any anywhere anywhere ctstate RELATED,ESTABLISHED 0 0 ACCEPT all -- any eth0 c6d5846467f3 172.22.0.0/24 1 176 ACCEPT udp -- any eth0 anywhere 64.42.179.50 udp dpt:1637 2463 148K ACCEPT all -- any tun0 anywhere anywhere ```
And iptables-legacy -vL -t nat which should look like:
```
Chain PREROUTING (policy ACCEPT 18779 packets, 2957K bytes)
pkts bytes target prot opt in out source destination
Chain INPUT (policy ACCEPT 291 packets, 28191 bytes) pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 7212 packets, 460K bytes) pkts bytes target prot opt in out source destination
This is the important rule
Chain POSTROUTING (policy ACCEPT 4718 packets, 310K bytes) pkts bytes target prot opt in out source destination 13677 916K MASQUERADE all -- any tun+ anywhere anywhere ```
The commands in post-rules.txt are a more precises version of @[email protected] solution in the comments.
Selectively chaining a VPN to another while allowing split tunnelling on clients?
Currently, I have two VPN clients on most of my devices:
- One for connecting to a LAN
- One commercial VPN for privacy reasons
I usually stay connected to the commercial VPN on all my devices, unless I need to access something on that LAN.
This setup has a few drawbacks:
- Most commercial VPN providers have a limit on the number of simulations connected clients
- I either obfuscate my IP or am able to access resources on that LAN, including my Pi-Hole fur custom DNS-based blocking
One possible solution for this would be to route all internet traffic through a VPN client on the router in the LAN and figuring out how to still be able to at least have a port open for the VPN docker container allowing access to the LAN. But then the ability to split tunnel around that would be pretty hard to achieve.
I want to be able to connect to a VPN host container on the LAN, which in turn routes all internet traffic through another VPN client container while allowing LAN traffic, but still be able to split tunnel specific applications on my Android/Linux/iOS devices.
Basically this:
+---------------------+ internet traffic +--------------------+ | | remote LAN traffic | | | Client |------------------->|VPN Host Container | | (Android/iOS/Linux) | |in remote LAN | | | | | +---------------------+ +--------------------+ | | | | remote LAN traffic| | internet traffic split tunneled traffic| |-------- | | | v v | +---------------------------+ +---------------------+ v | | | regular LAN or | +-----------+ | VPN Client Container | | internet connection | |remote LAN | | connects to commercial VPN| +---------------------+ +-----------+ | | | | +---------------------------+
Any recommendations on how to achieve this, especially considering client apps for Android and iOS with the ability to split tunnel per application?
Update:
Got it by following this guide.
Ended up modifying this setup to have better control over potential IP leakage