Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Hello everyone. Today I'd like to catch up on another paper, a popular one that has pushed a new fine-tuning trend called DPO (Direct Preference Optimization).
Included with the paper are a few open-source projects and code repos that support DPO training. If you are fine-tuning models, this is worth looking into!
DPO Arxiv Paper
- https://arxiv.org/abs/2305.18290
Try Fine-tuning w/ DPO using Axolotl
- https://github.com/OpenAccess-AI-Collective/axolotl
Try Fine-tuning w/ DPO using Llama Factory
- https://github.com/hiyouga/LLaMA-Factory
Try Fine-tuning w/DPO using Unsloth
- https://github.com/unslothai/unsloth
Now.. onto the paper!
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
> While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF).
> However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model.
> In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss.
> The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods.
> Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
{kind=link}
> Figure 1: DPO optimizes for human preferences while avoiding reinforcement learning. Existing methods for fine-tuning language models with human feedback first fit a reward model to a dataset of prompts and human preferences over pairs of responses, and then use RL to find a policy that maximizes the learned reward. In contrast, DPO directly optimizes for the policy best satisfying the preferences with a simple classification objective, fitting an implicit reward model whose corresponding optimal policy can be extracted in closed form
{kind=link}
> Figure 2: Left. The frontier of expected reward vs KL to the reference policy. DPO provides the highest expected reward for all KL values, demonstrating the quality of the optimization.
> Right. TL;DR summarization win rates vs. human-written summaries, using GPT-4 as evaluator. DPO exceeds PPO’s best-case performance on summarization, while being more robust to changes in the sampling temperature.
> Learning from preferences is a powerful, scalable framework for training capable, aligned language models. We have introduced DPO, a simple training paradigm for training language models from preferences without reinforcement learning.
> Rather than coercing the preference learning problem into a standard RL setting in order to use off-the-shelf RL algorithms, DPO identifies a mapping between language model policies and reward functions that enables training a language model to satisfy human preferences directly, with a simple cross-entropy loss, without reinforcement learning or loss of generality.
> With virtually no tuning of hyperparameters, DPO performs similarly or better than existing RLHF algorithms, including those based on PPO; DPO thus meaningfully reduces the barrier to training more language models from human preferences.
> Our results raise several important questions for future work. How does the DPO policy generalize out of distribution, compared with learning from an explicit reward function?
> Our initial results suggest that DPO policies can generalize similarly to PPO-based models, but more comprehensive study is needed. For example, can training with self-labeling from the DPO policy similarly make effective use of unlabeled prompts? On another front, how does reward over-optimization manifest in the direct preference optimization setting, and is the slight decrease in performance in Figure 3-right an instance of it?
> Additionally, while we evaluate models up to 6B parameters, exploration of scaling DPO to state-of-the-art models orders of magnitude larger is an exciting direction for future work. Regarding evaluations, we find that the win rates computed by GPT-4 are impacted by the prompt; future work may study the best way to elicit high-quality judgments from automated systems. Finally, many possible applications of DPO exist beyond training language models from human preferences, including training generative models in other modalities.
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
Hello everyone, I have another exciting Mamba paper to share. This being an MoE implementation of the state space model.
For those unacquainted with Mamba, let me hit you with a double feature (take a detour checking out these papers/code if you don't know what Mamba is):
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Official Mamba GitHub
- Example Implementation - Mamba-Chat
Now.. onto the MoE paper!
MoE-Mamba
Efficient Selective State Space Models with Mixture of Experts
> Maciej Pióro, Kamil Ciebiera, Krystian Król, Jan Ludziejewski, Sebastian Jaszczur
> State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models.
> We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance.
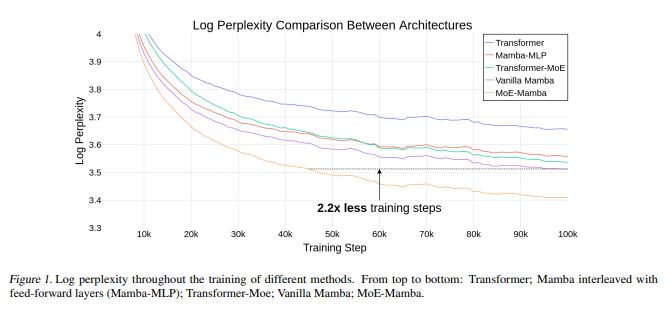{kind=link}
> Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
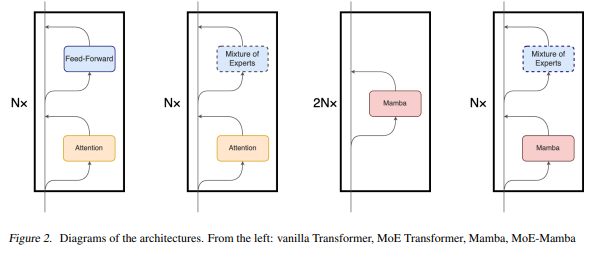{kind=link}
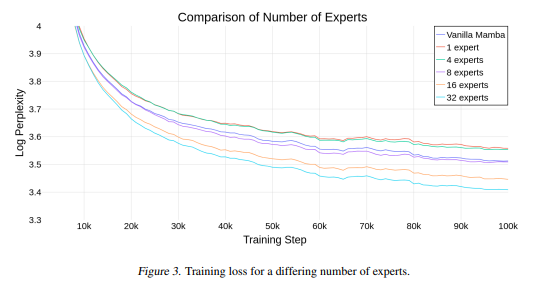{kind=link}
| Category | Hyperparameter | Value | |---------------------|----------------------------------|---------------------------------| | Model | Total Blocks | 8 (16 in Mamba) | | | dmodel | 512 | | Feed-Forward | df f | 2048 (with Attention) or 1536 (with Mamba) | | Mixture of Experts | dexpert | 2048 (with Attention) or 1536 (with Mamba) | | | Experts | 32 | | Attention | nheads | 8 | | Training | Training Steps | 100k | | | Context Length | 256 | | | Batch Size | 256 | | | LR | 1e-3 | | | LR Warmup | 1% steps | | | Gradient Clipping | 0.5 |
MoE seems like the logical way to move forward with Mamba, at this point, I'm wondering could there anything else holding it back? Curious to see more tools and implementations compare against some of the other trending transformer-based LLM stacks.
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Hello everyone, I have a very exciting paper to share with you today. This came out a little while ago, (like many other papers since my hiatus) so allow me to catch you up if you haven't read it already.
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Official Mamba GitHub
- Example Implementation - Mamba-Chat
- Bonus Paper: MoE-Mamba
Mamba
Linear-Time Sequence Modeling with Selective State Spaces
> Albert Gu, Tri Dao
{kind=link}
> Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module.
> Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language.
> We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements.
> First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token.
> Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba).
> Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences.
> As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics.
> On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
> (...) Mamba achieves state-of-the-art results on a diverse set of domains, where it matches or exceeds the performance of strong Transformer models. We are excited about the broad applications of selective state space models to build foundation models for different domains, especially in emerging modalities requiring long context such as genomics, audio, and video. Our results suggest that Mamba is a strong candidate to be a general sequence model backbone.
What are your thoughts on Mamba?
What sort of tokens per second are you seeing with your hardware? Mind sharing some notes on what you're running there? Super curious!
I was pleasantly surprised by many models of the Deepseek family. Verbose, but in a good way? At least that was my experience. Love to see it mentioned here.
Develop Alongside Local LLMs w/ Open Interpreter
I don't think this has been shared here before. Figured now is as good time as ever.
I'd like to share with everyone Open Interpreter.
Open Interpreter
Check it out here: https://github.com/KillianLucas/open-interpreter
> Open Interpreter lets LLMs run code (Python, Javascript, Shell, and more) locally. You can chat with Open Interpreter through a ChatGPT-like interface in your terminal by running $ interpreter after installing.
> This provides a natural-language interface to your computer's general-purpose capabilities:
> - Create and edit photos, videos, PDFs, etc. > - Control a Chrome browser to perform research > - Plot, clean, and analyze large datasets > - ...etc. > ⚠️ Note: You'll be asked to approve code before it's run.
Comparison to ChatGPT's Code Interpreter
> OpenAI's release of Code Interpreter with GPT-4 presents a fantastic opportunity to accomplish real-world tasks with ChatGPT.
> However, OpenAI's service is hosted, closed-source, and heavily restricted:
> - No internet access. > - Limited set of pre-installed packages. > - 100 MB maximum upload, 120.0 second runtime limit. > - State is cleared (along with any generated files or links) when the environment dies.
> Open Interpreter overcomes these limitations by running in your local environment. It has full access to the internet, isn't restricted by time or file size, and can utilize any package or library.
> This combines the power of GPT-4's Code Interpreter with the flexibility of your local development environment.
What open-source LLMs are you using in 2024?
There has been an overwhelming amount of new models hitting HuggingFace. I wanted to kick off a thread and see what open-source LLM has been your new daily driver?
Personally, I am using many Mistral/Mixtral models and a few random OpenHermes fine-tunes for flavor. I was also pleasantly surprised by some of the DeepSeek models. Those were fun to test.
I believe 2024 is the year open-source LLMs will catchup with GPT-3.5 and GPT-4. We're already most of the way there. Curious to hear what new contenders are on the block and how others feel about their performance/precision compared to other state-of-the-art (closed) source models.
FOSAI 2024
Hello everyone.
I'm back!
To anyone still reading - I hope you have been enjoying the rapid amount of progress we've seen in the space since my hiatus.
You'll be happy to hear I'm going to be periodically cleaning up some of the outdated resources in favor of new, updated documentation both on our frontpage and on our sidebar.
I know I also promised you all official FOSAI models on HuggingFace. I did not forget. Those are still in the pipeline. More info on that and other updates coming soon.
In the meantime, is there anything in terms of guides, resources, or notes that you'd like to see in particular? Let me know in the comments and I'll see where it might fit on the list.
Cheers!
Blaed
Blaed's Hiatus (Part I)
Hello everyone,
After some time away I have come to the realization that I have been neglecting a few personal projects and responsibilities by prioritizing staying in the know (over building / working towards other goals I set out to accomplish before 2024).
That being said, I decided it would be in my best interest to take a brief hiatus throughout the remainder of the year to tackle these tasks before they get out of hand (and no longer become a reality). I will be sharing notes here and there, but at much less frequency due to the work I'll be doing.
Some of these projects are resources for this community, others are totally different obligations I need to attend to.
You will be informed of the important updates, but I will be working mostly in the shadows - waiting and watching for the right moments to emerge.
On my long list of tasks is still getting our own fosai model on HuggingFace, which was going well until I ran out of funds. As much as I'd love to, it is no longer sustainable for me to keep paying out-of-pocket for fosai fine-tuning expenses.. lol.
I had a Mistral-7B fine-tune that almost completed its training - but failed at the final 4%. I had the adapter and weights semi-published, but they were unusable from whatever caused that hiccup. That's okay though, I will be applying for grants to help get this training workflow back off the ground (this time, with those pesky GPU costs covered).
If all else fails, I will turn to other methods.
I want you to know that throughout this hiatus, I am leaving the community to you guys. I want to let [email protected] organically grow (or slow) without my intervention. At the end of the day, I probably shouldn't be the only one sharing content here. I'm curious to see who sticks around and who does (or doesn't) post in my absence.
Shoutout everyone who has been sharing content, it does not go unnoticed. At least by me.
Whether content creator or casual lurker - you should know the activity of this community is not something I put a ton of expectations on so don't pressure yourself to try and keep this community 'alive' with content or comments if it doesn't feel natural or genuine. This community is not going anywhere, I'm just taking a break. We have already succeeded at the original fosai goal I set out to achieve. Now we must spend time building and developing our futures - collectively, and individually.
If you've been here since the beginning - thank you for reading and sticking around, but perhaps this is a good time for you to take a break from the AI news cycle too. This applies to everyone really, but it especially applies to all of you here. There was much innovation throughout the year and much more yet to come. If your FOMO is getting the best of you, consider subscribing to the YouTube content creators I've listed in this README. Otherwise, take a break, play some games, touch some grass or do something for yourself (and not for the sake of you thinking it needs to get done).
We'll be here for all of the future's wildest creations in this space, but taking a moment to develop yourself, be with family, (or spend time on one of your projects) is something you should consider doing if you have the ability to do so - no matter the pace of innovation. This is something I have forgotten, and something I will be reminding myself these coming weeks.
The future is now. The future is bright. The future is H.
Blaed
I appreciate this comment more than you will know. Thanks for sharing your thoughts.
It’s been a challenge realizing this time capsule is more than that - but a grassroots community and open-source project bigger than me. Adjusting the content to reflect shared interests has been a concept I have grappled with these last few weeks - especially as we exit some of the exciting innovations we saw earlier this year.
I think the type of content series you mention is the next step here - that being practical and pragmatic insights that illustrate / enable new workflows and applications.
That being said, this type of content creation will likely take more time than the journalistic reporting I’ve been doing - but I think it’s absolutely worth the effort and the next logical evolution of whatever this forum becomes.
Thanks again for your kind words. I work 5/6 day weeks in my tech job on top of this, so burnout is a real thing. I think I’ll go for a hike this week and reevaluate how to best proliferate and spread FOSAI.
If you’re reading this now and have ideas of your own - I’m all ears.
What kind of content do you want to see more of?
I have temporarily paused my weekly news reports to pause for a moment and take stock to better gauge the content you all care about (and want to see more of in this community).
What sort of topics or areas of content would you like for me to cover every week or so?
I won't guarantee I'll be the best journalist in this regard, but I'd be more than happy writing or R&D'ing about any concept that was useful or interesting for one of your ideas or workflows.
I am still somewhat busy brainstorming standardized workflows to fine-tune and publish a fosai model to HuggingFace, but I'm all ears between now and then.
Let me know if there is something you'd like to see more of here at [email protected]!
EDIT: I am actively rewriting all [email protected] guides, so that's one thing coming down the pipeline before the end of the month! Share more of your ideas or wish list items in the comments below.
Llama 2 / WizardLM Megathread
Llama 2 & WizardLM Megathread
Starting another model megathread to aggregate resources for any newcomers.
It's been awhile since I've had a chance to chat with some of these models so let me know some your favorites in the comments below.
There are many to choose from - sharing your experience could help someone else decide which to download for their use-case.
Thread Models:
---
Quantized Base Llama-2 Chat Models
Llama-2-7b-Chat
GPTQ
GGUF
AWQ
---
Llama-2-13B-chat
GPTQ
GGUF
AWQ
---
Llama-2-70B-chat
GPTQ
GGUF
AWQ
---
Quantized WizardLM Models
WizardLM-7B-V1.0+
GPTQ
GGUF
AWQ
---
WizardLM-13B-V1.0+
GPTQ
GGUF
AWQ
---
WizardLM-30B-V1.0+
GPTQ
- WizardLM-30B-uncensored-GPTQ
- WizardLM-Uncensored-SuperCOT-StoryTelling-30B-GPTQ
- WizardLM-33B-V1.0-Uncensored-GPTQ
GGUF
- WizardLM-30B-GGUF
- WizardLM-Uncensored-SuperCOT-StoryTelling-30B-GGUF
- WizardLM-33B-V1.0-Uncensored-GGUF
AWQ
---
Llama 2 Resources
> LLaMA 2 is a large language model developed by Meta and is the successor to LLaMA 1. LLaMA 2 is available for free for research and commercial use through providers like AWS, Hugging Face, and others. LLaMA 2 pretrained models are trained on 2 trillion tokens, and have double the context length than LLaMA 1. Its fine-tuned models have been trained on over 1 million human annotations.
Llama 2 Benchmarks
> Llama 2 shows strong improvements over prior LLMs across diverse NLP benchmarks, especially as model size increases: On well-rounded language tests like MMLU and AGIEval, Llama-2-70B scores 68.9% and 54.2% - far above MTP-7B, Falcon-7B, and even the 65B Llama 1 model.
Llama 2 Tutorials
Tutorials by James Briggs (also link above) are quick, hands-on ways for you to experiment with Llama 2 workflows. See also a poor man's guide to fine-tuning Llama 2. Check out Replicate if you want to host Llama 2 with an easy-to-use API.
---
Did I miss any models? What are some of your favorites? Which family/foundation/fine-tuning should we cover next?
Sharing brev.dev - A new platform for fine-tuning models on cloud GPUs
On my journey working on fine-tuning a model for [email protected] I stumbled across https://brev.dev/.
If you're looking at fine-tuning an LLM of your own - you should definitely give this platform a look. If not for the GPUs, at least for the other resources and guides. They support GPU powered notebooks, which is a feature I look for in these platforms. Their biome is also really helpful when you're looking to hack away at a prototype fast.
I am still testing it out, but I'd be keen to hear others opinions on it too.
> brev dev prices (est):
{kind=link}
Aside from the cloud GPU broker platform, they host a ton of really helpful guides and resources that you might be interested in. Check out their blog for more info. A few posts highlighted below.
- A Guide to Cost-Effectively Fine-Tuning Mistral
- How to fine-tune Llama 2 on your own data
- What you need to know about CUDA to get things done on Nvidia GPUs
- Run ControlNet on Stable Diffusion WebUI
- ..and More!
Let me know if you like brev or if there's another tool/workflow/process or platform you use that could enable others to fine-tune models of their own. Curious to see what else is out there!
HyperTech News Report #0003 - Expanding Horizons
cross-posted from: https://lemmy.world/post/6399678
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, October 6, 2023
>
> ## HyperTech News Report #0003
>
> Hello Everyone!
>
> This week highlights a wave of new papers and frameworks that expand upon LLM functionalities. With a tsunami of applications on the horizon I foresee a bedrock of tools to preceed. I'm not sure what kits and processes will end up part of this bedrock, but I hope some of these methods end up interesting or helpful to your workflow!
>
> ### Table of Contents
> - Community Changelog
> - Image of the Week
> - News
> - Tools & Frameworks
> - Papers
>
> ### Community Changelog
>
> - Pinned Mistral Megathread
> - We're R&D'ing FOSAI Models!
>
> ## Image of the Week
>
> !
>
> This image of the week comes from one of my own projects! I hope you don't mind me sharing.. I was really happy with this result. This was generated from an SDXL model I trained and host on Replicate. I use an mock ensemble approach to generate various game assets for an experimental roguelike I'm making with a colleague.
>
> My current method is not at all efficient, but I have fun. Right now, I have three SDXL models I interact with, each generating art I can use for my project. Andraxus takes care of wallpapers and in-game levels (this image you're seeing here), his
> in-game companion Biazera imagines characters and entities of this world, while Cerephelo tinkers and toils over the machinations within - crafting items, loot, powerups, etc.
>
> I've been hesitant self-promoting here. But if there's genuine interest in this project I would be more than happy sharing more details. It's still in pre-alpha development, but there were plans releasing all of the models we use as open-source (obviously). We're still working on the engine though. Let me know if you want to see more on this project.
>
> ---
>
> ## News
>
> ---
>
> 1. Arxiv Publications Workflow: A new workflow has been introduced that allows users to scrape search topics from Arxiv, converting the results into markdown (MD) format. This makes it easier to digest and understand topics from Arxiv published content. The tool, available on GitHub, is particularly useful for those who wish to delve deeper into research papers and run their own research processes.
>
> 2. Texting LLMs from Your Phone: A guide has been shared that enables users to communicate with their personal assistants via simple text messages. The process involves setting up a Twilio account, purchasing and registering a phone number, and then integrating it with the Replicate platform. The code, available on GitHub, makes it possible to send and receive messages from LLMs directly on one's phone.
>
> 3. Microsoft's AutoGen: Microsoft has released AutoGen, a tool designed to aid in the creation of autonomous LLM agents. Compatible with ChatGPT models, AutoGen facilitates the development of LLM applications using multiple agents that can converse with each other to solve tasks. The framework is customizable and allows for seamless human participation. More details can be found on GitHub.
>
> 4. Promptbench and ACE Framework: Promptbench is a new project focused on the evaluation and benchmarking of models. Stemming from the DyVal paper, it aims to provide reliable insights into model performance. On the other hand, the ACE Framework, designed for autonomous cognitive entities, offers a unique approach to agent tooling. While still in its early stages, it promises to bring about innovative implementations in the realms of personal assistants, game world NPCs, autonomous employees, and embodied robots.
>
> 5. Research Highlights: Several papers have been published that delve into the intricacies of LLMs. One paper introduces a method to enhance the zero-shot reasoning abilities of LLMs, while another, titled DyVal, proposes a dynamic evaluation protocol for LLMs. Additionally, the concept of Low-Rank Adapters (LoRA) ensembles for LLM fine-tuning has been explored, emphasizing the potential of using one model and dynamically swapping the fine-tuned QLoRA adapters.
>
> ---
>
> ## Tools & Frameworks
>
> ---
>
> #### Keep Up w/ Arxiv Publications
>
> - GitHub
> - Learn More
>
> Due to a drastic change in personal and work schedules, I've had to shift how I research and develop posts and projects for you guys. That being said, I found this workflow from the same author of the ACE Framework particularly helpful. It scrapes a search topic from Arxiv and returns a massive XML that is converted to markdown (MD) to then be used as an injectable context report for a LLM of your choosing (to further break down and understand topics) or as a well of information for the classic CTRL + F search. But at this point, info is aggregated (and human readable) from Arxiv published content.
>
> After reading abstractions you can further drill into each paper and dissect / run your own research processes as you see fit. There is definitely more room for automation and organization here I'm sure, but this has been a big resource for me lately so I wanted to proliferate it for others who might find it helpful too.
>
> #### Text LLMs from Your Phone
>
> - GitHub
> - Learn More
>
> I had an itch to make my personal assistants more accessible - so I started investigating ways I could simply text them from my iPhone (via simple sms). There are many other ways I could've done this, but texting has been something I always like to default to in communications. So, I found this cool guide that uses infra I already prefer (Replicate) and has a bonus LangChain integration - which opens up the door to a ton of other opportunities down the line.
>
> This tutorial was pretty straightforward - but to be honest, making the Twilio account, buying a phone number (then registering it) took the longest. The code itself takes less than 10 minutes to get up and running with ngrok. Super simple and straightforward there. The Twilio process? Not so much.. but it was worth the pain!
>
> I am still waiting on my phone number to be verified (so that the Replicate inference endpoint can actually send SMS back to me) but I ended the night successfully texting the server on my local PC. It was wild texting the Ahsoka example from my phone and seeing the POST response return (even though it didn't go through SMS I could still see the server successfully receive my incoming message/prompt). I think there's a lot of fun to be had giving casual phone numbers and personalities to assistants like this. Especially if you want to LangChain some functions beyond just the conversation. If there's more interest on this topic, I can share how my assistant evolves once it gets full access to return SMS. I am designing this to streamline my personal life, and if it proves to be useful I will absolutely release the project as open-source.
>
> #### AutoGen
>
> - GitHub
> - Learn More
> - Tutorial
>
> With Agents on the rise, tools and automation pipelines to build them have become increasingly more important to consider. It seems like Microsoft is well aware of this, and thus released AutoGen, a tool to help enable this automation tooling and creation of autonomous LLM agents. AutoGen is compatible with ChatGPT models and is being kitted for local LLMs as we speak.
>
> > AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
>
> #### Promptbench
>
> - GitHub
> - Learn More
>
> I recently found promptbench - a project that seems to have stemmed from the DyVal paper (shared below). I for one appreciate some of the new tools that are releasing focused around the evaluation and benchmarking of models. I hope we continue to see more evals, benchmarks, and projects that return us insights we can rely upon.
>
> #### ACE Framework
>
> !
>
> - GitHub
> - Learn More
>
> A new framework has been proposed and designed for autonomous cognitive entities. This appears similar to agents and their style of tooling, but with a different architecture approach? I don't believe implementation of this is ready, but it may be soon and something to keep an eye on.
>
> > There are many possible implementations of the ACE Framework. Rather than detail every possible permutation, here is a list of categories that we perceive as likely and viable.
>
> > Personal Assistant and/or Companion
>
> > - This is a self-contained version of ACE that is intended to interact with one user.
> > - Think of Cortana from HALO, Samantha from HER, or Joi from Blade Runner 2049. (yes, we recognize these are all sexualized female avatars)
> > - The idea would be to create something that is effectively a personal Executive Assistant that is able to coordinate, plan, research, and solve problems for you.
> This could be deployed on mobile, smart home devices, laptops, or web sites.
>
> > Game World NPC's
>
> > - This is a kind of game character that has their own personality, motivations, agenda, and objectives. Furthermore, they would have their own unique memories.
> > - This can give NPCs a much more realistic ability to pursue their own objectives, which should make game experiences much more dynamic and unpredictable, thus raising novelty.
> These can be adapted to 2D or 3D game engines such as PyGame, Unity, or Unreal.
>
> > Autonomous Employee
>
> > - This is a version of the ACE that is meant to carry out meaningful and productive work inside a corporation.
> > - Whether this is a digital CSR or backoffice worker depends on the deployment.
> > - It could also be a "digital team member" that primarily interacts via Discord, Slack, or Microsoft Teams.
>
> > Embodied Robot
>
> > The ACE Framework is ideal to create self-contained, autonomous machines. Whether they are domestic aid robots or something like WALL-E
>
> ---
>
> ## Papers
>
> ---
>
> Agent Instructs Large Language Models to be General Zero-Shot Reasoners
>
>
> > We introduce a method to improve the zero-shot reasoning abilities of large language models on general language understanding tasks. Specifically, we build an autonomous agent to instruct the reasoning process of large language models. We show this approach further unleashes the zero-shot reasoning abilities of large language models to more tasks. We study the performance of our method on a wide set of datasets spanning generation, classification, and reasoning. We show that our method generalizes to most tasks and obtains state-of-the-art zero-shot performance on 20 of the 29 datasets that we evaluate. For instance, our method boosts the performance of state-of-the-art large language models by a large margin, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%). Compared to zero-shot chain of thought, our improvement in reasoning is striking, with an average increase of 10.5%. With our method, Llama-2-70b-chat outperforms zero-shot GPT-3.5 Turbo by 10.2%.
>
> DyVal: Graph-informed Dynamic Evaluation of Large Language Models
>
>
> - https://llm-eval.github.io/
> - https://github.com/microsoft/promptbench
>
> > Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
>
> LoRA ensembles for large language model fine-tuning
>
> > Finetuned LLMs often exhibit poor uncertainty quantification, manifesting as overconfidence, poor calibration, and unreliable prediction results on test data or out-of-distribution samples. One approach commonly used in vision for alleviating this issue is a deep ensemble, which constructs an ensemble by training the same model multiple times using different random initializations. However, there is a huge challenge to ensembling LLMs: the most effective LLMs are very, very large. Keeping a single LLM in memory is already challenging enough: keeping an ensemble of e.g. 5 LLMs in memory is impossible in many settings. To address these issues, we propose an ensemble approach using Low-Rank Adapters (LoRA), a parameter-efficient fine-tuning technique. Critically, these low-rank adapters represent a very small number of parameters, orders of magnitude less than the underlying pre-trained model. Thus, it is possible to construct large ensembles of LoRA adapters with almost the same computational overhead as using the original model. We find that LoRA ensembles, applied on its own or on top of pre-existing regularization techniques, gives consistent improvements in predictive accuracy and uncertainty quantification.
>
> There is something to be discovered between LoRA, QLoRA, and ensemble/MoE designs. I am digging into this niche because of an interesting bit I heard from sentdex (if you want to skip to the part I'm talking about, go to 13:58). Around 15:00 minute mark he brings up QLoRA adapters (nothing new) but his approach was interesting.
>
> He eventually shares he is working on a QLoRA ensemble approach with skunkworks (presumably Boeing skunkworks). This confirmed my suspicion. Better yet - he shared his thoughts on how all of this could be done. Watch and support his video for more insights, but the idea boils down to using one model and dynamically swapping the fine-tuned QLoRA adapters. I think this is a highly efficient and unapplied approach. Especially in that MoE and ensemble realm of design. If you're reading this and understood anything I said - get to building! This is a seriously interesting idea that could yield positive results. I will share my findings when I find the time to dig into this more.
>
> ---
>
> ### Author's Note
>
> This post was authored by the moderator of [email protected] - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now... if you found anything about this post interesting, consider subscribing to [email protected] where you can join us on the journey into the great unknown!
>
> Until next time!
>
> #### Blaed
{kind=link}
{kind=link}
HyperTech News Report #0003 - Expanding Horizons
cross-posted from: https://lemmy.world/post/6399678
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, October 6, 2023
>
> ## HyperTech News Report #0003
>
> Hello Everyone!
>
> This week highlights a wave of new papers and frameworks that expand upon LLM functionalities. With a tsunami of applications on the horizon I foresee a bedrock of tools to preceed. I'm not sure what kits and processes will end up part of this bedrock, but I hope some of these methods end up interesting or helpful to your workflow!
>
> ### Table of Contents
> - Community Changelog
> - Image of the Week
> - News
> - Tools & Frameworks
> - Papers
>
> ### Community Changelog
>
> - Pinned Mistral Megathread
> - We're R&D'ing FOSAI Models!
>
> ## Image of the Week
>
> !
>
> This image of the week comes from one of my own projects! I hope you don't mind me sharing.. I was really happy with this result. This was generated from an SDXL model I trained and host on Replicate. I use an mock ensemble approach to generate various game assets for an experimental roguelike I'm making with a colleague.
>
> My current method is not at all efficient, but I have fun. Right now, I have three SDXL models I interact with, each generating art I can use for my project. Andraxus takes care of wallpapers and in-game levels (this image you're seeing here), his
> in-game companion Biazera imagines characters and entities of this world, while Cerephelo tinkers and toils over the machinations within - crafting items, loot, powerups, etc.
>
> I've been hesitant self-promoting here. But if there's genuine interest in this project I would be more than happy sharing more details. It's still in pre-alpha development, but there were plans releasing all of the models we use as open-source (obviously). We're still working on the engine though. Let me know if you want to see more on this project.
>
> ---
>
> ## News
>
> ---
>
> 1. Arxiv Publications Workflow: A new workflow has been introduced that allows users to scrape search topics from Arxiv, converting the results into markdown (MD) format. This makes it easier to digest and understand topics from Arxiv published content. The tool, available on GitHub, is particularly useful for those who wish to delve deeper into research papers and run their own research processes.
>
> 2. Texting LLMs from Your Phone: A guide has been shared that enables users to communicate with their personal assistants via simple text messages. The process involves setting up a Twilio account, purchasing and registering a phone number, and then integrating it with the Replicate platform. The code, available on GitHub, makes it possible to send and receive messages from LLMs directly on one's phone.
>
> 3. Microsoft's AutoGen: Microsoft has released AutoGen, a tool designed to aid in the creation of autonomous LLM agents. Compatible with ChatGPT models, AutoGen facilitates the development of LLM applications using multiple agents that can converse with each other to solve tasks. The framework is customizable and allows for seamless human participation. More details can be found on GitHub.
>
> 4. Promptbench and ACE Framework: Promptbench is a new project focused on the evaluation and benchmarking of models. Stemming from the DyVal paper, it aims to provide reliable insights into model performance. On the other hand, the ACE Framework, designed for autonomous cognitive entities, offers a unique approach to agent tooling. While still in its early stages, it promises to bring about innovative implementations in the realms of personal assistants, game world NPCs, autonomous employees, and embodied robots.
>
> 5. Research Highlights: Several papers have been published that delve into the intricacies of LLMs. One paper introduces a method to enhance the zero-shot reasoning abilities of LLMs, while another, titled DyVal, proposes a dynamic evaluation protocol for LLMs. Additionally, the concept of Low-Rank Adapters (LoRA) ensembles for LLM fine-tuning has been explored, emphasizing the potential of using one model and dynamically swapping the fine-tuned QLoRA adapters.
>
> ---
>
> ## Tools & Frameworks
>
> ---
>
> #### Keep Up w/ Arxiv Publications
>
> - GitHub
> - Learn More
>
> Due to a drastic change in personal and work schedules, I've had to shift how I research and develop posts and projects for you guys. That being said, I found this workflow from the same author of the ACE Framework particularly helpful. It scrapes a search topic from Arxiv and returns a massive XML that is converted to markdown (MD) to then be used as an injectable context report for a LLM of your choosing (to further break down and understand topics) or as a well of information for the classic CTRL + F search. But at this point, info is aggregated (and human readable) from Arxiv published content.
>
> After reading abstractions you can further drill into each paper and dissect / run your own research processes as you see fit. There is definitely more room for automation and organization here I'm sure, but this has been a big resource for me lately so I wanted to proliferate it for others who might find it helpful too.
>
> #### Text LLMs from Your Phone
>
> - GitHub
> - Learn More
>
> I had an itch to make my personal assistants more accessible - so I started investigating ways I could simply text them from my iPhone (via simple sms). There are many other ways I could've done this, but texting has been something I always like to default to in communications. So, I found this cool guide that uses infra I already prefer (Replicate) and has a bonus LangChain integration - which opens up the door to a ton of other opportunities down the line.
>
> This tutorial was pretty straightforward - but to be honest, making the Twilio account, buying a phone number (then registering it) took the longest. The code itself takes less than 10 minutes to get up and running with ngrok. Super simple and straightforward there. The Twilio process? Not so much.. but it was worth the pain!
>
> I am still waiting on my phone number to be verified (so that the Replicate inference endpoint can actually send SMS back to me) but I ended the night successfully texting the server on my local PC. It was wild texting the Ahsoka example from my phone and seeing the POST response return (even though it didn't go through SMS I could still see the server successfully receive my incoming message/prompt). I think there's a lot of fun to be had giving casual phone numbers and personalities to assistants like this. Especially if you want to LangChain some functions beyond just the conversation. If there's more interest on this topic, I can share how my assistant evolves once it gets full access to return SMS. I am designing this to streamline my personal life, and if it proves to be useful I will absolutely release the project as open-source.
>
> #### AutoGen
>
> - GitHub
> - Learn More
> - Tutorial
>
> With Agents on the rise, tools and automation pipelines to build them have become increasingly more important to consider. It seems like Microsoft is well aware of this, and thus released AutoGen, a tool to help enable this automation tooling and creation of autonomous LLM agents. AutoGen is compatible with ChatGPT models and is being kitted for local LLMs as we speak.
>
> > AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
>
> #### Promptbench
>
> - GitHub
> - Learn More
>
> I recently found promptbench - a project that seems to have stemmed from the DyVal paper (shared below). I for one appreciate some of the new tools that are releasing focused around the evaluation and benchmarking of models. I hope we continue to see more evals, benchmarks, and projects that return us insights we can rely upon.
>
> #### ACE Framework
>
> !
>
> - GitHub
> - Learn More
>
> A new framework has been proposed and designed for autonomous cognitive entities. This appears similar to agents and their style of tooling, but with a different architecture approach? I don't believe implementation of this is ready, but it may be soon and something to keep an eye on.
>
> > There are many possible implementations of the ACE Framework. Rather than detail every possible permutation, here is a list of categories that we perceive as likely and viable.
>
> > Personal Assistant and/or Companion
>
> > - This is a self-contained version of ACE that is intended to interact with one user.
> > - Think of Cortana from HALO, Samantha from HER, or Joi from Blade Runner 2049. (yes, we recognize these are all sexualized female avatars)
> > - The idea would be to create something that is effectively a personal Executive Assistant that is able to coordinate, plan, research, and solve problems for you.
> This could be deployed on mobile, smart home devices, laptops, or web sites.
>
> > Game World NPC's
>
> > - This is a kind of game character that has their own personality, motivations, agenda, and objectives. Furthermore, they would have their own unique memories.
> > - This can give NPCs a much more realistic ability to pursue their own objectives, which should make game experiences much more dynamic and unpredictable, thus raising novelty.
> These can be adapted to 2D or 3D game engines such as PyGame, Unity, or Unreal.
>
> > Autonomous Employee
>
> > - This is a version of the ACE that is meant to carry out meaningful and productive work inside a corporation.
> > - Whether this is a digital CSR or backoffice worker depends on the deployment.
> > - It could also be a "digital team member" that primarily interacts via Discord, Slack, or Microsoft Teams.
>
> > Embodied Robot
>
> > The ACE Framework is ideal to create self-contained, autonomous machines. Whether they are domestic aid robots or something like WALL-E
>
> ---
>
> ## Papers
>
> ---
>
> Agent Instructs Large Language Models to be General Zero-Shot Reasoners
>
>
> > We introduce a method to improve the zero-shot reasoning abilities of large language models on general language understanding tasks. Specifically, we build an autonomous agent to instruct the reasoning process of large language models. We show this approach further unleashes the zero-shot reasoning abilities of large language models to more tasks. We study the performance of our method on a wide set of datasets spanning generation, classification, and reasoning. We show that our method generalizes to most tasks and obtains state-of-the-art zero-shot performance on 20 of the 29 datasets that we evaluate. For instance, our method boosts the performance of state-of-the-art large language models by a large margin, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%). Compared to zero-shot chain of thought, our improvement in reasoning is striking, with an average increase of 10.5%. With our method, Llama-2-70b-chat outperforms zero-shot GPT-3.5 Turbo by 10.2%.
>
> DyVal: Graph-informed Dynamic Evaluation of Large Language Models
>
>
> - https://llm-eval.github.io/
> - https://github.com/microsoft/promptbench
>
> > Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
>
> LoRA ensembles for large language model fine-tuning
>
> > Finetuned LLMs often exhibit poor uncertainty quantification, manifesting as overconfidence, poor calibration, and unreliable prediction results on test data or out-of-distribution samples. One approach commonly used in vision for alleviating this issue is a deep ensemble, which constructs an ensemble by training the same model multiple times using different random initializations. However, there is a huge challenge to ensembling LLMs: the most effective LLMs are very, very large. Keeping a single LLM in memory is already challenging enough: keeping an ensemble of e.g. 5 LLMs in memory is impossible in many settings. To address these issues, we propose an ensemble approach using Low-Rank Adapters (LoRA), a parameter-efficient fine-tuning technique. Critically, these low-rank adapters represent a very small number of parameters, orders of magnitude less than the underlying pre-trained model. Thus, it is possible to construct large ensembles of LoRA adapters with almost the same computational overhead as using the original model. We find that LoRA ensembles, applied on its own or on top of pre-existing regularization techniques, gives consistent improvements in predictive accuracy and uncertainty quantification.
>
> There is something to be discovered between LoRA, QLoRA, and ensemble/MoE designs. I am digging into this niche because of an interesting bit I heard from sentdex (if you want to skip to the part I'm talking about, go to 13:58). Around 15:00 minute mark he brings up QLoRA adapters (nothing new) but his approach was interesting.
>
> He eventually shares he is working on a QLoRA ensemble approach with skunkworks (presumably Boeing skunkworks). This confirmed my suspicion. Better yet - he shared his thoughts on how all of this could be done. Watch and support his video for more insights, but the idea boils down to using one model and dynamically swapping the fine-tuned QLoRA adapters. I think this is a highly efficient and unapplied approach. Especially in that MoE and ensemble realm of design. If you're reading this and understood anything I said - get to building! This is a seriously interesting idea that could yield positive results. I will share my findings when I find the time to dig into this more.
>
> ---
>
> ### Author's Note
>
> This post was authored by the moderator of [email protected] - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now... if you found anything about this post interesting, consider subscribing to [email protected] where you can join us on the journey into the great unknown!
>
> Until next time!
>
> #### Blaed
HyperTech News Report #0003 - Expanding Horizons
cross-posted from: https://lemmy.world/post/6399678
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, October 6, 2023
>
> ## HyperTech News Report #0003
>
> Hello Everyone!
>
> This week highlights a wave of new papers and frameworks that expand upon LLM functionalities. With a tsunami of applications on the horizon I foresee a bedrock of tools to preceed. I'm not sure what kits and processes will end up part of this bedrock, but I hope some of these methods end up interesting or helpful to your workflow!
>
> ### Table of Contents
> - Community Changelog
> - Image of the Week
> - News
> - Tools & Frameworks
> - Papers
>
> ### Community Changelog
>
> - Pinned Mistral Megathread
> - We're R&D'ing FOSAI Models!
>
> ## Image of the Week
>
> !
>
> This image of the week comes from one of my own projects! I hope you don't mind me sharing.. I was really happy with this result. This was generated from an SDXL model I trained and host on Replicate. I use an mock ensemble approach to generate various game assets for an experimental roguelike I'm making with a colleague.
>
> My current method is not at all efficient, but I have fun. Right now, I have three SDXL models I interact with, each generating art I can use for my project. Andraxus takes care of wallpapers and in-game levels (this image you're seeing here), his
> in-game companion Biazera imagines characters and entities of this world, while Cerephelo tinkers and toils over the machinations within - crafting items, loot, powerups, etc.
>
> I've been hesitant self-promoting here. But if there's genuine interest in this project I would be more than happy sharing more details. It's still in pre-alpha development, but there were plans releasing all of the models we use as open-source (obviously). We're still working on the engine though. Let me know if you want to see more on this project.
>
> ---
>
> ## News
>
> ---
>
> 1. Arxiv Publications Workflow: A new workflow has been introduced that allows users to scrape search topics from Arxiv, converting the results into markdown (MD) format. This makes it easier to digest and understand topics from Arxiv published content. The tool, available on GitHub, is particularly useful for those who wish to delve deeper into research papers and run their own research processes.
>
> 2. Texting LLMs from Your Phone: A guide has been shared that enables users to communicate with their personal assistants via simple text messages. The process involves setting up a Twilio account, purchasing and registering a phone number, and then integrating it with the Replicate platform. The code, available on GitHub, makes it possible to send and receive messages from LLMs directly on one's phone.
>
> 3. Microsoft's AutoGen: Microsoft has released AutoGen, a tool designed to aid in the creation of autonomous LLM agents. Compatible with ChatGPT models, AutoGen facilitates the development of LLM applications using multiple agents that can converse with each other to solve tasks. The framework is customizable and allows for seamless human participation. More details can be found on GitHub.
>
> 4. Promptbench and ACE Framework: Promptbench is a new project focused on the evaluation and benchmarking of models. Stemming from the DyVal paper, it aims to provide reliable insights into model performance. On the other hand, the ACE Framework, designed for autonomous cognitive entities, offers a unique approach to agent tooling. While still in its early stages, it promises to bring about innovative implementations in the realms of personal assistants, game world NPCs, autonomous employees, and embodied robots.
>
> 5. Research Highlights: Several papers have been published that delve into the intricacies of LLMs. One paper introduces a method to enhance the zero-shot reasoning abilities of LLMs, while another, titled DyVal, proposes a dynamic evaluation protocol for LLMs. Additionally, the concept of Low-Rank Adapters (LoRA) ensembles for LLM fine-tuning has been explored, emphasizing the potential of using one model and dynamically swapping the fine-tuned QLoRA adapters.
>
> ---
>
> ## Tools & Frameworks
>
> ---
>
> #### Keep Up w/ Arxiv Publications
>
> - GitHub
> - Learn More
>
> Due to a drastic change in personal and work schedules, I've had to shift how I research and develop posts and projects for you guys. That being said, I found this workflow from the same author of the ACE Framework particularly helpful. It scrapes a search topic from Arxiv and returns a massive XML that is converted to markdown (MD) to then be used as an injectable context report for a LLM of your choosing (to further break down and understand topics) or as a well of information for the classic CTRL + F search. But at this point, info is aggregated (and human readable) from Arxiv published content.
>
> After reading abstractions you can further drill into each paper and dissect / run your own research processes as you see fit. There is definitely more room for automation and organization here I'm sure, but this has been a big resource for me lately so I wanted to proliferate it for others who might find it helpful too.
>
> #### Text LLMs from Your Phone
>
> - GitHub
> - Learn More
>
> I had an itch to make my personal assistants more accessible - so I started investigating ways I could simply text them from my iPhone (via simple sms). There are many other ways I could've done this, but texting has been something I always like to default to in communications. So, I found this cool guide that uses infra I already prefer (Replicate) and has a bonus LangChain integration - which opens up the door to a ton of other opportunities down the line.
>
> This tutorial was pretty straightforward - but to be honest, making the Twilio account, buying a phone number (then registering it) took the longest. The code itself takes less than 10 minutes to get up and running with ngrok. Super simple and straightforward there. The Twilio process? Not so much.. but it was worth the pain!
>
> I am still waiting on my phone number to be verified (so that the Replicate inference endpoint can actually send SMS back to me) but I ended the night successfully texting the server on my local PC. It was wild texting the Ahsoka example from my phone and seeing the POST response return (even though it didn't go through SMS I could still see the server successfully receive my incoming message/prompt). I think there's a lot of fun to be had giving casual phone numbers and personalities to assistants like this. Especially if you want to LangChain some functions beyond just the conversation. If there's more interest on this topic, I can share how my assistant evolves once it gets full access to return SMS. I am designing this to streamline my personal life, and if it proves to be useful I will absolutely release the project as open-source.
>
> #### AutoGen
>
> - GitHub
> - Learn More
> - Tutorial
>
> With Agents on the rise, tools and automation pipelines to build them have become increasingly more important to consider. It seems like Microsoft is well aware of this, and thus released AutoGen, a tool to help enable this automation tooling and creation of autonomous LLM agents. AutoGen is compatible with ChatGPT models and is being kitted for local LLMs as we speak.
>
> > AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
>
> #### Promptbench
>
> - GitHub
> - Learn More
>
> I recently found promptbench - a project that seems to have stemmed from the DyVal paper (shared below). I for one appreciate some of the new tools that are releasing focused around the evaluation and benchmarking of models. I hope we continue to see more evals, benchmarks, and projects that return us insights we can rely upon.
>
> #### ACE Framework
>
> !
>
> - GitHub
> - Learn More
>
> A new framework has been proposed and designed for autonomous cognitive entities. This appears similar to agents and their style of tooling, but with a different architecture approach? I don't believe implementation of this is ready, but it may be soon and something to keep an eye on.
>
> > There are many possible implementations of the ACE Framework. Rather than detail every possible permutation, here is a list of categories that we perceive as likely and viable.
>
> > Personal Assistant and/or Companion
>
> > - This is a self-contained version of ACE that is intended to interact with one user.
> > - Think of Cortana from HALO, Samantha from HER, or Joi from Blade Runner 2049. (yes, we recognize these are all sexualized female avatars)
> > - The idea would be to create something that is effectively a personal Executive Assistant that is able to coordinate, plan, research, and solve problems for you.
> This could be deployed on mobile, smart home devices, laptops, or web sites.
>
> > Game World NPC's
>
> > - This is a kind of game character that has their own personality, motivations, agenda, and objectives. Furthermore, they would have their own unique memories.
> > - This can give NPCs a much more realistic ability to pursue their own objectives, which should make game experiences much more dynamic and unpredictable, thus raising novelty.
> These can be adapted to 2D or 3D game engines such as PyGame, Unity, or Unreal.
>
> > Autonomous Employee
>
> > - This is a version of the ACE that is meant to carry out meaningful and productive work inside a corporation.
> > - Whether this is a digital CSR or backoffice worker depends on the deployment.
> > - It could also be a "digital team member" that primarily interacts via Discord, Slack, or Microsoft Teams.
>
> > Embodied Robot
>
> > The ACE Framework is ideal to create self-contained, autonomous machines. Whether they are domestic aid robots or something like WALL-E
>
> ---
>
> ## Papers
>
> ---
>
> Agent Instructs Large Language Models to be General Zero-Shot Reasoners
>
>
> > We introduce a method to improve the zero-shot reasoning abilities of large language models on general language understanding tasks. Specifically, we build an autonomous agent to instruct the reasoning process of large language models. We show this approach further unleashes the zero-shot reasoning abilities of large language models to more tasks. We study the performance of our method on a wide set of datasets spanning generation, classification, and reasoning. We show that our method generalizes to most tasks and obtains state-of-the-art zero-shot performance on 20 of the 29 datasets that we evaluate. For instance, our method boosts the performance of state-of-the-art large language models by a large margin, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%). Compared to zero-shot chain of thought, our improvement in reasoning is striking, with an average increase of 10.5%. With our method, Llama-2-70b-chat outperforms zero-shot GPT-3.5 Turbo by 10.2%.
>
> DyVal: Graph-informed Dynamic Evaluation of Large Language Models
>
>
> - https://llm-eval.github.io/
> - https://github.com/microsoft/promptbench
>
> > Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
>
> LoRA ensembles for large language model fine-tuning
>
> > Finetuned LLMs often exhibit poor uncertainty quantification, manifesting as overconfidence, poor calibration, and unreliable prediction results on test data or out-of-distribution samples. One approach commonly used in vision for alleviating this issue is a deep ensemble, which constructs an ensemble by training the same model multiple times using different random initializations. However, there is a huge challenge to ensembling LLMs: the most effective LLMs are very, very large. Keeping a single LLM in memory is already challenging enough: keeping an ensemble of e.g. 5 LLMs in memory is impossible in many settings. To address these issues, we propose an ensemble approach using Low-Rank Adapters (LoRA), a parameter-efficient fine-tuning technique. Critically, these low-rank adapters represent a very small number of parameters, orders of magnitude less than the underlying pre-trained model. Thus, it is possible to construct large ensembles of LoRA adapters with almost the same computational overhead as using the original model. We find that LoRA ensembles, applied on its own or on top of pre-existing regularization techniques, gives consistent improvements in predictive accuracy and uncertainty quantification.
>
> There is something to be discovered between LoRA, QLoRA, and ensemble/MoE designs. I am digging into this niche because of an interesting bit I heard from sentdex (if you want to skip to the part I'm talking about, go to 13:58). Around 15:00 minute mark he brings up QLoRA adapters (nothing new) but his approach was interesting.
>
> He eventually shares he is working on a QLoRA ensemble approach with skunkworks (presumably Boeing skunkworks). This confirmed my suspicion. Better yet - he shared his thoughts on how all of this could be done. Watch and support his video for more insights, but the idea boils down to using one model and dynamically swapping the fine-tuned QLoRA adapters. I think this is a highly efficient and unapplied approach. Especially in that MoE and ensemble realm of design. If you're reading this and understood anything I said - get to building! This is a seriously interesting idea that could yield positive results. I will share my findings when I find the time to dig into this more.
>
> ---
>
> ### Author's Note
>
> This post was authored by the moderator of [email protected] - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now... if you found anything about this post interesting, consider subscribing to [email protected] where you can join us on the journey into the great unknown!
>
> Until next time!
>
> #### Blaed
HyperTech News Report #0003 - Expanding Horizons
🤖 Happy FOSAI Friday! 🚀
Friday, October 6, 2023
HyperTech News Report #0003
Hello Everyone!
This week highlights a wave of new papers and frameworks that expand upon LLM functionalities. With a tsunami of applications on the horizon I foresee a bedrock of tools to preceed. I'm not sure what kits and processes will end up part of this bedrock, but I hope some of these methods end up interesting or helpful to your workflow!
Table of Contents
Community Changelog
Image of the Week
This image of the week comes from one of my own projects! I hope you don't mind me sharing.. I was really happy with this result. This was generated from an SDXL model I trained and host on Replicate. I use an mock ensemble approach to generate various game assets for an experimental roguelike I'm making with a colleague.
My current method is not at all efficient, but I have fun. Right now, I have three SDXL models I interact with, each generating art I can use for my project. Andraxus takes care of wallpapers and in-game levels (this image you're seeing here), his in-game companion Biazera imagines characters and entities of this world, while Cerephelo tinkers and toils over the machinations within - crafting items, loot, powerups, etc.
I've been hesitant self-promoting here. But if there's genuine interest in this project I would be more than happy sharing more details. It's still in pre-alpha development, but there were plans releasing all of the models we use as open-source (obviously). We're still working on the engine though. Let me know if you want to see more on this project.
---
News
---
-
Arxiv Publications Workflow: A new workflow has been introduced that allows users to scrape search topics from Arxiv, converting the results into markdown (MD) format. This makes it easier to digest and understand topics from Arxiv published content. The tool, available on GitHub, is particularly useful for those who wish to delve deeper into research papers and run their own research processes.
-
Texting LLMs from Your Phone: A guide has been shared that enables users to communicate with their personal assistants via simple text messages. The process involves setting up a Twilio account, purchasing and registering a phone number, and then integrating it with the Replicate platform. The code, available on GitHub, makes it possible to send and receive messages from LLMs directly on one's phone.
-
Microsoft's AutoGen: Microsoft has released AutoGen, a tool designed to aid in the creation of autonomous LLM agents. Compatible with ChatGPT models, AutoGen facilitates the development of LLM applications using multiple agents that can converse with each other to solve tasks. The framework is customizable and allows for seamless human participation. More details can be found on GitHub.
-
Promptbench and ACE Framework:
Promptbenchis a new project focused on the evaluation and benchmarking of models. Stemming from the DyVal paper, it aims to provide reliable insights into model performance. On the other hand, the ACE Framework, designed forautonomous cognitive entities, offers a unique approach to agent tooling. While still in its early stages, it promises to bring about innovative implementations in the realms of personal assistants, game world NPCs, autonomous employees, and embodied robots. -
Research Highlights: Several papers have been published that delve into the intricacies of LLMs. One paper introduces a method to enhance the zero-shot reasoning abilities of LLMs, while another, titled DyVal, proposes a dynamic evaluation protocol for LLMs. Additionally, the concept of Low-Rank Adapters (LoRA) ensembles for LLM fine-tuning has been explored, emphasizing the potential of using one model and dynamically swapping the fine-tuned QLoRA adapters.
---
Tools & Frameworks
---
Keep Up w/ Arxiv Publications
Due to a drastic change in personal and work schedules, I've had to shift how I research and develop posts and projects for you guys. That being said, I found this workflow from the same author of the ACE Framework particularly helpful. It scrapes a search topic from Arxiv and returns a massive XML that is converted to markdown (MD) to then be used as an injectable context report for a LLM of your choosing (to further break down and understand topics) or as a well of information for the classic CTRL + F search. But at this point, info is aggregated (and human readable) from Arxiv published content.
After reading abstractions you can further drill into each paper and dissect / run your own research processes as you see fit. There is definitely more room for automation and organization here I'm sure, but this has been a big resource for me lately so I wanted to proliferate it for others who might find it helpful too.
Text LLMs from Your Phone
I had an itch to make my personal assistants more accessible - so I started investigating ways I could simply text them from my iPhone (via simple sms). There are many other ways I could've done this, but texting has been something I always like to default to in communications. So, I found this cool guide that uses infra I already prefer (Replicate) and has a bonus LangChain integration - which opens up the door to a ton of other opportunities down the line.
This tutorial was pretty straightforward - but to be honest, making the Twilio account, buying a phone number (then registering it) took the longest. The code itself takes less than 10 minutes to get up and running with ngrok. Super simple and straightforward there. The Twilio process? Not so much.. but it was worth the pain!
I am still waiting on my phone number to be verified (so that the Replicate inference endpoint can actually send SMS back to me) but I ended the night successfully texting the server on my local PC. It was wild texting the Ahsoka example from my phone and seeing the POST response return (even though it didn't go through SMS I could still see the server successfully receive my incoming message/prompt). I think there's a lot of fun to be had giving casual phone numbers and personalities to assistants like this. Especially if you want to LangChain some functions beyond just the conversation. If there's more interest on this topic, I can share how my assistant evolves once it gets full access to return SMS. I am designing this to streamline my personal life, and if it proves to be useful I will absolutely release the project as open-source.
AutoGen
With Agents on the rise, tools and automation pipelines to build them have become increasingly more important to consider. It seems like Microsoft is well aware of this, and thus released AutoGen, a tool to help enable this automation tooling and creation of autonomous LLM agents. AutoGen is compatible with ChatGPT models and is being kitted for local LLMs as we speak.
> AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
Promptbench
I recently found promptbench - a project that seems to have stemmed from the DyVal paper (shared below). I for one appreciate some of the new tools that are releasing focused around the evaluation and benchmarking of models. I hope we continue to see more evals, benchmarks, and projects that return us insights we can rely upon.
ACE Framework
A new framework has been proposed and designed for autonomous cognitive entities. This appears similar to agents and their style of tooling, but with a different architecture approach? I don't believe implementation of this is ready, but it may be soon and something to keep an eye on.
> There are many possible implementations of the ACE Framework. Rather than detail every possible permutation, here is a list of categories that we perceive as likely and viable.
> Personal Assistant and/or Companion
> - This is a self-contained version of ACE that is intended to interact with one user. > - Think of Cortana from HALO, Samantha from HER, or Joi from Blade Runner 2049. (yes, we recognize these are all sexualized female avatars) > - The idea would be to create something that is effectively a personal Executive Assistant that is able to coordinate, plan, research, and solve problems for you. This could be deployed on mobile, smart home devices, laptops, or web sites.
> Game World NPC's
> - This is a kind of game character that has their own personality, motivations, agenda, and objectives. Furthermore, they would have their own unique memories. > - This can give NPCs a much more realistic ability to pursue their own objectives, which should make game experiences much more dynamic and unpredictable, thus raising novelty. These can be adapted to 2D or 3D game engines such as PyGame, Unity, or Unreal.
> Autonomous Employee
> - This is a version of the ACE that is meant to carry out meaningful and productive work inside a corporation. > - Whether this is a digital CSR or backoffice worker depends on the deployment. > - It could also be a "digital team member" that primarily interacts via Discord, Slack, or Microsoft Teams.
> Embodied Robot
> The ACE Framework is ideal to create self-contained, autonomous machines. Whether they are domestic aid robots or something like WALL-E
---
Papers
---
Agent Instructs Large Language Models to be General Zero-Shot Reasoners
> We introduce a method to improve the zero-shot reasoning abilities of large language models on general language understanding tasks. Specifically, we build an autonomous agent to instruct the reasoning process of large language models. We show this approach further unleashes the zero-shot reasoning abilities of large language models to more tasks. We study the performance of our method on a wide set of datasets spanning generation, classification, and reasoning. We show that our method generalizes to most tasks and obtains state-of-the-art zero-shot performance on 20 of the 29 datasets that we evaluate. For instance, our method boosts the performance of state-of-the-art large language models by a large margin, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%). Compared to zero-shot chain of thought, our improvement in reasoning is striking, with an average increase of 10.5%. With our method, Llama-2-70b-chat outperforms zero-shot GPT-3.5 Turbo by 10.2%.
DyVal: Graph-informed Dynamic Evaluation of Large Language Models
- https://llm-eval.github.io/
- https://github.com/microsoft/promptbench
> Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
LoRA ensembles for large language model fine-tuning
> Finetuned LLMs often exhibit poor uncertainty quantification, manifesting as overconfidence, poor calibration, and unreliable prediction results on test data or out-of-distribution samples. One approach commonly used in vision for alleviating this issue is a deep ensemble, which constructs an ensemble by training the same model multiple times using different random initializations. However, there is a huge challenge to ensembling LLMs: the most effective LLMs are very, very large. Keeping a single LLM in memory is already challenging enough: keeping an ensemble of e.g. 5 LLMs in memory is impossible in many settings. To address these issues, we propose an ensemble approach using Low-Rank Adapters (LoRA), a parameter-efficient fine-tuning technique. Critically, these low-rank adapters represent a very small number of parameters, orders of magnitude less than the underlying pre-trained model. Thus, it is possible to construct large ensembles of LoRA adapters with almost the same computational overhead as using the original model. We find that LoRA ensembles, applied on its own or on top of pre-existing regularization techniques, gives consistent improvements in predictive accuracy and uncertainty quantification.
There is something to be discovered between LoRA, QLoRA, and ensemble/MoE designs. I am digging into this niche because of an interesting bit I heard from sentdex (if you want to skip to the part I'm talking about, go to 13:58). Around 15:00 minute mark he brings up QLoRA adapters (nothing new) but his approach was interesting.
He eventually shares he is working on a QLoRA ensemble approach with skunkworks (presumably Boeing skunkworks). This confirmed my suspicion. Better yet - he shared his thoughts on how all of this could be done. Watch and support his video for more insights, but the idea boils down to using one model and dynamically swapping the fine-tuned QLoRA adapters. I think this is a highly efficient and unapplied approach. Especially in that MoE and ensemble realm of design. If you're reading this and understood anything I said - get to building! This is a seriously interesting idea that could yield positive results. I will share my findings when I find the time to dig into this more.
---
Author's Note
This post was authored by the moderator of [email protected] - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
Thanks for Reading!
This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now...
Until next time!
Blaed
Anyone else working with retrieval augmented generation? (RAG)
What have been your experiences with it? What does your workflow look like?
Curious to hear preferred models and pipelines!
Frameworks
Databases
Tutorials
Am I missing any other RAG resources?
This is on the horizon - I will definitely be making a post on the workflow and process once it is figured out.
I am actively exploring this question.
So far - it’s been the best performing 7B model I’ve been able to get my hands on. Anyone running consumer hardware could get a GGUF version running on almost any dedicated GPU/CPU combo.
I am a firm believer there is more performance and better quality of responses to be found in smaller parameter models. Not too mention interesting use cases you could apply fine-tuning an ensemble approach.
A lot of people sleep on 7B, but I think Mistral is a little different - there’s a lot of exploring to be had finding these use cases but I think they’re out there waiting to be discovered.
I’ll definitely report back on how the first attempt at fine-tuning this myself goes. Until then, I suppose it would be great for any roleplay or basic chat interaction. Given it’s low headroom - it’s much more lightweight to prototype with outside of the other families and model sizes.
If anyone else has a particular use case for 7B models - let us know here. Curious to know what others are doing with smaller params.
Mistral 7B Megathread
Starting a Mistral Megathread to aggregate resources.
This is my new favorite 7B model. It is really good for what it is. I am excited to see what we can tune together. I will be using this thread as a living document, expect a lot of changes and notes, revisions and updates.
Let me know if there's something in particular you want to see here. I will be adding to this thread throughout my fine-tuning journey with Mistral.
Mistral Model Megathread
---
Key
Link #1 - Base ModelLink #2 - Instruct Model
---
Quantized Base Models from TheBloke
GPTQ
- https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ
- https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GPTQ
GGUF
- https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF
- https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF
AWQ
- https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ
- https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-AWQ
---
Quantized Samantha Models from TheBloke
GPTQ
- https://huggingface.co/TheBloke/samantha-mistral-7B-GPTQ
- https://huggingface.co/TheBloke/samantha-mistral-instruct-7B-GPTQ
GGUF
- https://huggingface.co/TheBloke/samantha-mistral-7B-GGUF
- https://huggingface.co/TheBloke/samantha-mistral-instruct-7B-GGUF
AWQ
- https://huggingface.co/TheBloke/samantha-mistral-7B-AWQ
- https://huggingface.co/TheBloke/samantha-mistral-instruct-7B-AWQ
---
Quantized Kimiko Models from TheBloke
GPTQ
- https://huggingface.co/TheBloke/Kimiko-Mistral-7B-GPTQ
GGUF
- https://huggingface.co/TheBloke/Kimiko-Mistral-7B-GGUF
AWQ
- https://huggingface.co/TheBloke/Kimiko-Mistral-7B-AWQ
---
Quantized Dolphin Models from TheBloke
GPTQ
- https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GPTQ
GGUF
- https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-GGUF
AWQ
- https://huggingface.co/TheBloke/dolphin-2.0-mistral-7B-AWQ
---
Quantized Orca Models from TheBloke
GPTQ
- https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GPTQ
GGUF
- https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF
AWQ
- https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ
---
Quantized Airoboros Models from TheBloke
GPTQ
- https://huggingface.co/TheBloke/airoboros-mistral2.2-7B-GPTQ
GGUF
- https://huggingface.co/TheBloke/airoboros-mistral2.2-7B-GGUF
AWQ
- https://huggingface.co/TheBloke/airoboros-mistral2.2-7B-AWQ
---
If you like to run any of the quantized/optimized models from TheBloke, do visit the full model pages from each of the quantized model cards to see and support the developers of each fine-tuned model.
- Mistral - Mistral.ai
- Mistral Samantha - Eric Hartford
- Mistral Kimiko - nRuaif
- Mistral Dolphin - Eric Hartford
- Mistral OpenOrca - OpenOrca/Alignment Lab
- Mistral Airoboros - teknium
AutoGen - Enabling Next Generation LLM Applications
Today I am very excited to share with you AutoGen - a new framework for enabling next generation LLM applications.
This new process published by Microsoft Research Blog details a method on how to easily and efficiently deploy agentic LLMs across your workflows.
{kind=link}
AutoGen
> It requires a lot of effort and expertise to design, implement, and optimize a workflow that can leverage the full potential of large language models (LLMs). Automating these workflows has tremendous value. As developers begin to create increasingly complex LLM-based applications, workflows will inevitably grow more intricate. The potential design space for such workflows could be vast and complex, thereby heightening the challenge of orchestrating an optimal workflow with robust performance.
> AutoGen is a framework for simplifying the orchestration, optimization, and automation of LLM workflows. It offers customizable and conversable agents that leverage the strongest capabilities of the most advanced LLMs, like GPT-4, while addressing their limitations by integrating with humans and tools and having conversations between multiple agents via automated chat.
> With AutoGen, building a complex multi-agent conversation system boils down to:
- Defining a set of agents with specialized capabilities and roles.
- Defining the interaction behavior between agents, i.e., what to reply when an agent receives messages from another agent.
{kind=link}
> Both steps are intuitive and modular, making these agents reusable and composable. For example, to build a system for code-based question answering, one can design the agents and their interactions as in Figure 2. Such a system is shown to reduce the number of manual interactions needed from 3x to 10x in applications like supply-chain optimization(opens in new tab). Using AutoGen leads to more than a 4x reduction in coding effort.
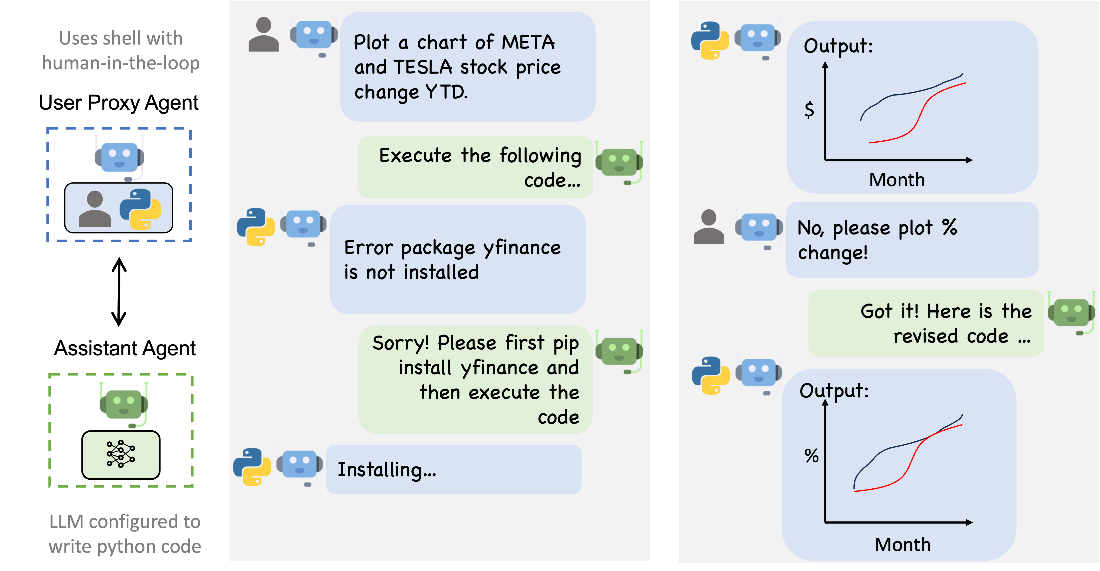{kind=link}
> The agent conversation-centric design has numerous benefits, including that it:
- Naturally handles ambiguity, feedback, progress, and collaboration. Enables effective coding-related tasks, like tool use with back-and-forth troubleshooting.
- Allows users to seamlessly opt in or opt out via an agent in the chat.
- Achieves a collective goal with the cooperation of multiple specialists.
{kind=link}
---
Getting Started
AutoGen (in preview) is freely available as a Python package. To install it, run
pip install pyautogen
You can quickly enable a powerful experience with just a few lines of code:
import autogen
assistant = autogen.AssistantAgent("assistant")
user_proxy = autogen.UserProxyAgent("user_proxy")
user_proxy.initiate_chat(assistant, message="Show me the YTD gain of 10 largest technology companies as of today.")
# This triggers automated chat to solve the task
> Check examples for a wide variety of tasks: https://microsoft.github.io/autogen/docs/Examples/AutoGen-AgentChat
---
Learn More
I feel like I've been mentioning this a lot lately, but agentic LLMs and emergent AI tooling frameworks like these are what will to return us the most value. If you're looking to expand your horizons beyond just chatting with LLMs, integrating agentic tools is an interesting topic to explore. There is much to be built in this space of exciting AI!
What do you think are some of the most interesting use cases for AGI?
To me, it's pretty obvious how AGI can change the world.
I'm curious to hear everyone else's thoughts on this.
What I find interesting is how useful these tools are (even with the imperfections that you mention). Imagine a world where this level of intelligence has a consistent low error rate.
Semantic computation and agentic function calling with this level of accuracy will revolutionize the world. It’s only a matter of time, adoption, and availability.
Google has absolutely tanked for me these last few years. It revolutionized the world by revolutionizing search. But ChatGPT has done the same, now better - and in a much more interesting way.
I’ll take a 10 second prompt process over 20 minutes of hunting down (advertised) paged results any day of the week.
I have learned everything I have about AI through AI mentors.
Having the ability to ask endless amounts of seemingly stupid questions does a lot for me.
Not to mention some of the analogies and abstractions you can utilize to build your own learning process.
I’d love to see schools start embracing the power of personalized mentors for each and every student. I think some of the first universities to embrace this methodology will produce some incredible minds.
You should try fine-tuning that legalese model! I know I’d use it. Could be a great business idea or generally helpful for anyone you release it to.
I cannot understate how nice it is having a coding assistant 24/7.
I’m curious to see how projects like ChatDev evolve over time. I think agentic tooling is going to take us to some very sci-fi looking territory.
Semantic computation is the future.
I never considered 8 - 11. Those are really interesting use cases. I’m with you on every other point. I’m particularly interested in solving the messy unstructured notes scenario. I really feel you on that one. I’ll see what I can do!
What I find particularly exciting is that we’re seeing this evolution in real-time.
Can you imagine what these models might look like in 2 years? 5? 10?
There is a remarkable future on the horizon. I hope everyone gets an equal chance to be a part of it.
I could not agree more. I really enjoy Andrej Karpathy’s model where in the future AGI does 99% of the technical work and the human in the loop does the creative and critical 1%.
Why do you like LLMs?
Genuinely curious.
Why do you like LLMs? What hopes do you have for AI & AGI in our near and distant future?
Mistral seems to be the popular choice. I think it's the most open-source friendly out of the bunch. I will keep function calling in mind as I design some of our models! Thanks for bringing that up.
I appreciate your comment! It seems like we're going the fine-tuning route. I think it's the best way to do it too. I'm still glad I floated around the foundation model idea. We'll get one of our own eventually!
Welcome to the show! Enthusiast or not, you are part of [email protected]. Your input is valued and your curiosity is encouraged!
It seems like we'll be starting with Mistral - which means the model will be completely open-source under the Apache 2.0 License.
All fine-tunings I release under fosai would be licensed under the same Apache 2.0 agreement, giving you and everyone else complete permissions to modify, download, distribute, and deploy this model as you see fit. It would make the model commercially viable out-of-the-box without any restrictions set by a corporation or entity.
I'm also not a copyright lawyer, so someone correct me If I'm wrong here but if I fine-tune Mistral (which I probably will) and also release the derivative under the Apache 2.0 license - you own the version you choose to download completely. You don't need to adhere to a usage policy. You are still responsible for what you end up doing with your model (within all local applicable laws), but you also don't have to worry about Meta (or some other entity) revoking or changing their policy/usage/terms at some point in the future. You are free to do whatever you want with an Apache licensed model.
At the end of the day, Llama 2 is owned and distributed by Meta AI, which has some of those restrictions I mentioned, even though it is somewhat open-source. Here is the license. Some notes from it that might be worth mentioning:
- You need to credit Meta whenever you share Llama 2 by including a specific notice.
- You have to follow all laws and regulations when using Llama 2 and also adhere to Meta's usage policy.
- You can't use Llama 2 to make or improve other similar software (large language models), except Llama 2 itself or things derived from it.
- If your company or its affiliates have more than 700 million users a month, you can't just use this agreement. You have to ask Meta for special permission.
I wouldn’t want risk a legal battle with a company the size of Meta, so I’d vote for the other options just to be one the safe side.
Completely reasonable, I agree.
Do you have the resources for this to be a viable option?
Where there's a will, there's a way. I could muster the resources for a foundation model, but it's definitely not the most optimal option we have at our disposal. The original plan was a.) fine-tune a small series (short-term) b.) release a foundation model (long-term). I only recently considered skipping Plan A, but I'm glad I've got feedback to prevent me from doing otherwise. Would've enjoyed the process nonetheless.
Are you confident that the end result will be better than Mistral? If not, why spend that much on creating something equivalent or possibly even inferior?
Of course not. I don't do this to be the best. I offer to do this to understand. To document how to build and release a foundation model from start to finish is knowledge that could be valuable to someone else - which is why I was willing to skip ahead if that was a topic others wanted to dive more into. For me, it's more about the friends we make along the way. There is grace in polishing a product and being the best, but I'd like to think there is also something special in doing something just to document it for others. There is something fulfilling exploring a new frontier with nothing but sheer curiosity.
Then there’s also the question of how long a model is going to be relevant before some other new model with all the latest innovations is released and makes everything else look outdated… Even if you can create a model which rivals llama-2 and mistral now, are you going to create a new one to compete with llama-3 and mistral-2 when those come along?
I also don't do this to be relevant. To be a part of the this is enough for me. In my studies, I have found something bigger than me - I see myself doing this for many years so I know I'll be around to see it evolve and current technologies become irrelevant in time. If you consider existing alongside these models as 'competing' then yes, I would be doing that I suppose.
Sorry for the negativity but I think creating a base model sounds likely to be a massive waste of resources. If you have a lot of time and money to throw at this project, I think it would be much better spent on fine-tuning existing models.
Don't worry, it was very great feedback. Exactly why I made this post! I'm glad you made all your points. It's the same logic I had (and the same logic I was willing to throw aside for others). At this point, it seems like fine-tuning is what most of you want to see. So fine-tuning it shall be!
This will be a fine-tuned model, so it may inherit some of the permissions and license agreements as its foundation model and have other implications depending on your country or local law.
You are correct, if we chose Llama 2 - the fine-tune derivative may be subject to their original license terms. However, Apache 2.0 would apply and transfer to something like a fine-tuned version of Mistral, since its base license is also Apache 2.0.
If there is enough support - I'd be more than open to creating an entirely new foundation model family. This would be a larger undertaking than this initial fine-tuning deployment, but building a completely free FOSAI foundation family of models was the penultimate goal of this project so if this garners enough attention I could absolutely put energy and focus into creating another Mistral-like product instead of splashing around with fine-tuning.
Whatever would help everyone the most! I like where you're thinking though, I'm going to update the thread to include an option to vote for a new foundation family instead. At the end of the day, it's likely I'll do all of the above - I'm just not sure in what order yet..
I have come to believe Moore's law is finite, and we're starting to see the exponential end of it. This leads me to believe (or want to believe) there are other looming breakthroughs for compute, optimization, and/or hardware on the horizon. That, or crazy powerful GPUs are about to be a common household investment.
I keep thinking about what George Hotz is doing in regards to this. He explained on his podcast with Lex Fridman that there is much to be explored in optimization, both with quantization of software and acceleration of hardware.
His idea of 'commoditize the petabyte' is really cool. I think it's worth bringing up here, especially given the fact it appears one of his biggest goals right now is solving the at-home compute problem. But in a way that you could actually run something like a 180B model in-house no problem.
George Hotz' tinybox
($15,000)
738 FP16 TFLOPS144 GB GPU RAM5.76 TB/s RAM bandwidth30 GB/s model load bandwidth (big llama loads in around 4 seconds)AMD EPYC CPU1600W (one 120V outlet)Runs 65B FP16 LLaMA out of the box (using tinygrad, subject to software development risks)
You can pre-order one now. You have $15k laying around, right? Lol.
It's definitely not easy (or cheap) now, but I think it's going to get significantly easier to build and deploy large models for all kinds of personal use cases in our near and distant futures.
If you're serving/hosting models, it's also worth checking out vLLM if you haven't already: https://github.com/vllm-project/vllm
Loved to read everyone's comments on this one. If you're here and reading this post now, check out this related thread - you might be interested!