https://app.element.io/#/room/#xq_icebreaker:matrix.org
These are recommended lists:
Update On August 2nd, 2023, negotiations between community representatives and representatives of the company concluded with an agreement being reached. The details of the agreement can be found at

> To reference Stack Overflow moderator Machavity, AI chatbots are like parrots. ChatGPT, for example, doesn’t understand the responses it gives you; it simply associates a given prompt with information it has access to and regurgitates plausible-sounding sentences. It has no way to verify that the responses it’s providing you with are accurate. ChatGPT is not a writer, a programmer, a scientist, a physicist, or any other kind of expert our network of sites is dependent upon for high-value content. When prompted, it’s just stringing together words based upon the information it was trained with. It does not understand what it’s saying. That lack of understanding yields unverified information presented in a way that sounds smart or citations that may not support the claims, if the citations aren’t wholly fictitious. Furthermore, the ease with which a user can simply copy and paste an AI-generated response simply moves the metaphorical “parrot” from the chatbot to the user. They don’t really understand what they’ve just copied and presented as an answer to a question.
> Content posted without innate domain understanding, but written in a “smart” way, is dangerous to the integrity of the Stack Exchange network’s goal: To be a repository of high-quality question and answer content.
> AI-generated responses also represent a serious honesty issue. Submitting AI-generated content without attribution to the source of the content, as is common in such a scenario, is plagiarism. This makes AI-generated content eligible for deletion per the Stack Exchange Code of Conduct and rules on referencing. However, in order for moderators to act upon that, they must identify it as AI generated content, which the private AI generated content policy limits to extremely narrow circumstances which happen in only a very low percentage of AI generated content that is posted to the sites.
c/o https://social.coop/@[email protected]/110490440953441074
On the hypocrisy of Copyright law and its functionality
The enforcement of copyright law is really simple. If you were a kid who used Napster in the early 2000s to download the latest album by The Offspring or Destiny's Child, because you couldn't afford the CD, then you need to go to court! And potentially face criminal sanctions or punitive damages to...
This person has nailed the hypocricy:
> The enforcement of copyright law is really simple.
> If you were a kid who used Napster in the early 2000s to download the latest album by The Offspring or Destiny's Child, because you couldn't afford the CD, then you need to go to court! And potentially face criminal sanctions or punitive damages to the RIAA for each song you download, because you're an evil pirate! You wouldn't steal a car! Creators must be paid!
> If you created educational videos on YouTube in the 2010s, and featured a video or audio clip, then even if it's fair use, and even if it's used to make a legitimate point, you're getting demonetised. That's assuming your videos don't disappear or get shadow banned or your account isn't shut entirely. Oh, and good luck finding your way through YouTube's convoluted DMCA process! All creators are equal in deserving pay, but some are more equal than others!
> And if you're a corporation with a market capitalisation of US$1.5 trillion (Google/Alphabet) or US$2.3 billion (Microsoft), then you can freely use everyone's intellectual property to train your generative AI bots. Suddenly creators don't deserve to be paid a cent.
> Apparently, an individual downloading a single file is like stealing a car. But a trillion-dollar corporation stealing every car is just good business.
> @[email protected] @technology #technology #tech #economics #copyright #ArtificialIntelligence #capitalism #IntellectualProperty @[email protected] #law #legal #economics
> Writing is a skill and like any other skill the only way to get good at it is to practice. Blogging is ideal for this. Blogging is hardly ever long-form writing so writing posts is a good way to practice in bite-sized chunks. A side benefit of writing is that it’s a necessary component to being a good thinker and writing, as Paul Graham says [1b], is a precursor to thinking. Guo agrees with this and also notes that writing helps him clarify his thinking.
> He gives several other reasons to blog including
> * Sharing knowledge > * Learning things > * Learning how he’s wrong
[1b1] https://twitter.com/paulg/status/1639954042372730881 [1b2] https://nitter.net/paulg/status/1639954042372730881#m
Discovering Nice Servers On Mastodon and The Fediverse

> This is a small curated list of servers to help new users joining Mastodon and the wider Fediverse. All the servers listed have public sign-ups open, have promised to obey certain standards of reliability and responsible moderation, and have opted in to being listed here.
> a curated list of servers that comply with certain standards of moderation and reliability
c/o https://social.coop/@[email protected]/110327847898986508
Criteria:
> p.s. Some differences between FediGarden and JoinMastodon:
> -Servers with over 50k total users will not be listed
> -Both Mastodon and non-Mastodon Fedi servers can be listed (though there are still only a few of these at the moment)
> -Lists have an ever-changing randomised order and do not prioritise large servers or servers with immediate signups
> -Forks are indicated too, if people want a Glitch or Hometown server for example
> -Founding dates are shown
https://mstdn.social/@feditips/110327890887600075
Thread Concerning How Fediverse's Decentralised Forms Means That 'There Is No Daddy'
> What you're missing is the comforting certainty that there's Somebody In Charge. And that this Somebody cares about you, cares about the money they can make off of you, and certainly cares about the 'content' you're producing for them so that they can both mine you and others for precious, precious moneybucks and sell you to their advertisers.
> Well, sorry to break it to you, but there are Many Someones In Charge and no one--not anyone--literally no one at all--can tell them all what to do.
> Ever hear the expression about herding cats?
> That's the decentralized anarchy at the heart of all of this, and what makes it work is communities talking with each other openly, and being able to disassociate from communities that do not suit them--or that might be actively destructive to them.
Leaked Internal Google Document Claims Open Source AI Will Outcompete Google and OpenAI
Leaked Internal Google Document Claims Open Source AI Will Outcompete Google and OpenAI
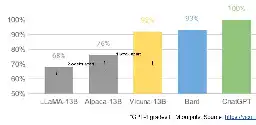
> In many ways, this shouldn’t be a surprise to anyone. The current renaissance in open source LLMs comes hot on the heels of a renaissance in image generation. The similarities are not lost on the community, with many calling this the “Stable Diffusion moment” for LLMs.
> In both cases, low-cost public involvement was enabled by a vastly cheaper mechanism for fine tuning called low rank adaptation, or LoRA, combined with a significant breakthrough in scale (latent diffusion for image synthesis, Chinchilla for LLMs). In both cases, access to a sufficiently high-quality model kicked off a flurry of ideas and iteration from individuals and institutions around the world. In both cases, this quickly outpaced the large players.
> These contributions were pivotal in the image generation space, setting Stable Diffusion on a different path from Dall-E. Having an open model led to product integrations, marketplaces, user interfaces, and innovations that didn’t happen for Dall-E.
> The effect was palpable: rapid domination in terms of cultural impact vs the OpenAI solution, which became increasingly irrelevant. Whether the same thing will happen for LLMs remains to be seen, but the broad structural elements are the same.
Discussion thread for this topic found here:
https://news.ycombinator.com/item?id=35813322
On The Risks of Permissive Licensing
That was a good read. Luke Smith put it more expressively, IMO, with particular noteworthyness in a ubiquitous real world example that that MINIX is actually the most predominant desktop/laptop, and server platform OS in the planet. Try to do a good thing by using a permissive license and have you...

> Also, the AGPL isn’t something that commercial operations are afraid of. There are plenty of examples of industry using AGPL software.
> The problem (problems, in reality, are actually just opportunities for solutions) is that scheming “software and appliance” companies wish to close source their products (whether they created them or not) under their proprietary brands. They can, and have, launched litigation against those infringing upon or co-opting their trade and service marks, even patents based on their own products - that sometimes was developed and sold without a single scrap of code authored by them. The only thing a permissive license requires is a Copyright notice, somewhere obscure.
> “Ohh yeah, we did include a bit of some open source code” is all they gotta admit to when pressed - they never can be forced to divulge that they didn’t write diddly squat!
> Maybe… Just maybe… It’s… Your code.
> With respect to the patent, all they need to do is change one little thing about the process in which the existing software worked and patent that. Whole 'nother thing though and I’m not here to teach how to engage in patent trolling, like we did at IBM, lolz.
> When they do add to that code, their code is under a completely arbitrarily determined proprietary license, locking down the entire product (written by someone else), as closed source under the terms of a license they decide upon - nothing at all remains of the permissively licensed product… Except that obscure little Copyright notice somewhere.
> AGPL merely enforces that anything you add to an initially AGPL licensed work must be made available on demand by the people using your product…
Thread concerning surveillance technologies and practices within callcentre type employment roles
Largely unknown to a wider public, some of the biggest employers include so-called 'business process outsourcing' firms. They run call centers and provide everything from sales and customer services to back-office work and content moderation, with several 100k workers. Thread:
I've been in my workshop making things ever since, and the covid lockdown was the perfect time to make some new videos, trying to pass on some of what I've learnt. So if you're interested do try my new 'Secret Life of Components' These old films were remastered and upscaled by Norman Margolus from...

Classic educational video.
Nice use of demonstrations and archive material.
First good night’s sleep ive had in weeks. I suddenly woke up and realized all the items that need fixing in AP, and for the most part, how to fix them. I need to write this up before I forget. I came to a conclusion that it’s going to be really hard to fix AP in the 1.x branch, especially within...

> We are going to need an Activity Pub 2.0 which fixes the major pain points in the eco system. It must be backward compatible with 1.x, but will introduce new, more scalable, extensible, interoperable ways of doing things for a larger federation and ecosystem. Systems using 1.x can signal it, and those using 2.0 should accept 1.x activities. Those using 2.x can run an upgraded protocol, and when signaling has reached a certain threshold, the old 1.x API can be sunset.
> I think the first task on this track is to broadly outline the high level areas that need an upgrade, before drilling into the details. Split AP into its logical functions e.g. identity, payload, discovery, serializations (including parsing), namespacing, ontologies, authentication, signatures, c2s/s2s, large media types, version signalling, extensibility, authorization etc.
> Different people will want to work on different things, so maybe the first step is to poll people to see what they want, what are the pain points, and then propose a new spec that gets most of it in.
An interesting thread by on moderation in the fediverse
Let's talk about #FediProblems unrelated to #Bluesky today. The prevelance of #Discord in #Fediverse #moderation. #Discord is a centralized service with a history of violating the #gdpr and being generally not #privacy friendly. In terms of data security, it's messages are comparable to #DMs on ...
> I understand the reason for this - organization and coordination are difficult tasks. And the team responsible for resolving conflicts should not itself be a source of misunderstanding and conflict.
> For this purpose #discord is a very useful, but flawed tool. And alternatives (e.g. #Matrix, #IRC, #Email and #Jitsi) have their own issues - some are just down to network effects, others actually lack features making them less useful for coordination.
https://social.coop/@[email protected]/110294521149402911
> But one thing I do want to talk about is the recent idea, I saw probably during a discussion of @atomicpoet:
> #Fediverse #autonomous #moderation - the idea that both moderation actions and the coordination of moderation teams should be completely run through the #Fediverse - thus removing a disconnect between #userspace and #moderatorspace on a technological level.
https://social.coop/@[email protected]/110294531671678800
> The advantages to organizing #moderation on the fediverse include in my opinion: > - better #privacy, as even when using unencrypted DMs, as long as they stay on the instance being moderated, the instance retains #digitalsovereignty. > - better interactions between moderators and members. #Mastodon, especially, creates an illusion that only one person/account is the face of the instance. That this false for most instances, is a well-known fact. But this is not reflected by the #Mastodon software.
https://social.coop/@[email protected]/110294839498602666
Feedback on lockin for knowledge-management systems concernng Trello
Attached: 1 image I've been using Trello for more than 5 years to collect my thoughts, excerpts, and notes to finally realize that I'm pretty locked in. It took me one weekend and some Python to create a workflow to migrate all my boards, including attachments to Obsidian … If you're stuck too, let...
> Ive been using Trello for more than 5 years to collect my thoughts, excerpts, and notes to finally realize that I'm pretty locked in. It took me one weekend and some Python to create a workflow to migrate all my boards, including attachments to Obsidian … If you're stuck too, let me know via pm, and I'm glad to share my experiences …
> #obsidian #trello #research
Combobulate is a package that adds advanced structured editing and movement to many programming modes in Emacs. Here's how it works, and how it can enrich your editing experience in Emacs.

Just discovered Combobulate:
> Combobulate takes the syntax tree created by tree-sitter and uses it to provide structured editing and movement. It can do it better than traditional, imperative or regexp-based approaches, because it has a perfect understanding of your code. That means there’s never any ambiguity as to whether { ... } is a statement block or an object in Javascript, for example.
https://www.masteringemacs.org/article/combobulate-structured-movement-editing-treesitter
https://github.com/mickeynp/combobulate
c/o https://social.coop/@[email protected]/109788552701305561
Im looking forward to Emacs 29 maturing so that I can utilise this functionality.
xtdb/xtdb: General-purpose bitemporal database for SQL, Datalog & graph queries
Bitemporal and dynamic relational database for SQL and Datalog. Developed by @juxt - GitHub - xtdb/xtdb: Bitemporal and dynamic relational database for SQL and Datalog. Developed by @juxt

> XTDB is a general purpose database with graph-oriented bitemporal indexes. Datalog, SQL & EQL queries are supported, and Java, HTTP & Clojure APIs are provided.
> XTDB follows an unbundled architectural approach, which means that it is assembled from decoupled components through the use of an immutable log and document store at the core of its design. A range of storage options are available for embedded usage and cloud native scaling.
> Bitemporal indexing of schemaless documents enables broad possibilities for creating layered extensions on top, such as to add additional transaction, query, and schema capabilities. In addition to SQL, XTDB supplies a Datalog query interface that can be used to express complex joins and recursive graph traversals.
https://github.com/xtdb/xtdb
https://www.xtdb.com/learn
A thread by reiver ⊼ (Charles) :batman: , on missing professional-class-types within the fediverse communities
2/ • there are no or very, very few: • UX researchers, • UI designers, • illustrators, • industrial researchers, • QA specialists, • project managers, • strategists. This is bad! If you want to produce 'good' software that people will want to and like using, you need these people! Someone needs...
> Here is a problem with most open-source software projects have, including most #Fediverse software —
> • there are no or very, very few: > • UX researchers, > • UI designers, > • illustrators, > • industrial researchers, > • QA specialists, > • project managers, > • strategists.
> This is bad!
> If you want to produce 'good' software that people will want to and like using, you need these people!
> Someone needs to do these roles!
> Some software developers can also do some of these roles. And that is awesome. But most software developers cannot
> I see this same problem with a lot of #Fediverse software, too
> The thing is, I know there are people with these skills — UX researchers, UI designers, illustrators, industrial researchers, QA specialists, project managers, strategists — who want to get involved with #openSource projects.
> But they don't know how.
Research in cognitive geography
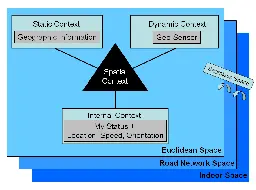
> Displaying information through maps has shaped how humans sense space and direction. Communicating effectively through maps is a challenge for many cartographers. For example, symbols, their color, and their relative size have an important role to play in the interaction between the map and the mapmaker.
> The study of Geo-ontology also has interested researchers in this field. Geo-ontology involves the study of the variations among different cultures in how they view and sense landforms, how to communicate spatial knowledge with other cultures while overcoming such barriers, an understanding of the cognitive aspects of spatial relations, and how to represent them in computational models.[7] For example, there might be some geographic meaning that might not be well explained using words. There might be some differences in understanding when spatial information is explained verbally instead of non-verbal form.
c/o doopledi, in room Social Coding FSDL https://matrix.to/#/#socialcoding-foundations:matrix.org
an experimental chat system built within Gemini
> This is galaxy-chat-server, a prototype of a chat system designed within an implementation of a standards-compliant Gemini server.
> galaxy-chat-server is a fork of egalaxyd, a gemini/spartan file server > https://sr.ht/~slondr/egalaxyd/
c/o https://social.coop/@[email protected]/110254055600009856
Ask ChatGPT to write you a Beyoncé song and it will churn out something cringey – but completely convincing. Lydia Spencer-Elliott speaks to experts about the future of AI in music and the threats and opportunities it poses for songwriters

> “AI goes around the internet and scrapes all of the lyrics but never provides any credits,” says Bryan-Kinns. “If an AI makes a song, gets famous, went to No 1, who would get money from them? Certainly not the people in the huge dataset of millions of songs. ...
> Last summer, the [UK] government set out proposals to amend copyright laws that would allow AI creators to exploit musicians’ back catalogues without permission or compensation.
I’ve always liked having a record of what I’ve done on a project and a place for notes. That’s often been a notebook, updates to GitHub/GitLab/JIRA issues/tickets, or maybe blog entries. Those all have problems. In reading Masters of Doom I came across a passage which described the intense environm...

> I like keeping track of things I do but I like doing it with as little overhead as possible. Hence I have years of food data tracking but that only really started being real when the ability to enter that data became so simple as to be effortless. The same is true for development on projects. I want to see how things evolved. When I look at something years later and think to myself, “What the hell was I thinking?” it’s nice to be able to look back at notes from that time. Likewise as I’m working on something and I have a thought pop in my head like, “We need to fix this later,” or, “Gee wouldn’t it be nice if this program did this thing,” it’d be nice to have a place to collect all of that and have it be something which doesn’t interrupt my train of thought. I’ve tried collecting that in issue trackers and the like but honestly I’ve never been able to keep up with that. Issue trackers that become the reservoir for things to do start having inefficient signal to noise ratios. Even when I thinned out old issues it often proved hard to find what I was looking for as well. Lastly it also disrupts the flow.
> Carmack’s “.plan” file concept was an absolutely perfect solution to this problem. It’s a simple text file you have open and you put in short statements with a simple key that you can decipher instantly. It’s searchable so you can easily find stuff. It’s shareable so it doubles as providing status as well as a means of keeping track of your own thoughts. Lastly, everything about the project is in one place. I don’t have notes in one place, issues in another, feature ideas elsewhere, etc. While I liked Carmack’s idea I have tweaked it a bit for my own purposes.
> The first tweak I have is that each project gets its own DevLog. I started off trying to have it in one big file but since I work on multiple projects it just didn’t scale well. Since these are text files there is no disadvantage to having them split out since search tools can just as easily traverse multiple text files in a directory as one big text file. In the rare cases where something I’m working on is related to both projects I make a footnote in the one about seeing something in the other or some other mechanism. It’s such an uncommon occurrence even on projects that have entanglements that I don’t worry about it.
===== References in text
https://bookshop.org/books/masters-of-doom-how-two-guys-created-an-empire-and-transformed-pop-culture-9780812972153/9780812972153
https://twitter.com/JohnCarmack
https://github.com/ESWAT/john-carmack-plan-archive