
Casual Perchance
-
a more customizeable t2i
https://perchance.org/starlitsky uses t2iav instead of t2i. It basically is t2i minus the feedback button and click requirements with a bunch of the stuff uncustomizeable in t2i customizeable. Since t2i has light mode and dark mode, styling is split in to both. Say if you use this or want to use it and I will improve it; not currently touching it otherwise because the styles feel way less magical than my main gen and I'd rather make a game :)
-
A short story about the recent Generator Manager situation
I'm briefly back again! 😃 I want to post this to highlight some sort of event happening with my generator hub page, as well as how I was able to fix it.
So, pretty recently, my Generator Manager was suddenly entirely broken for a few days. The DevTools console threw these errors, and I was confused for a moment thinking it was me constantly editing the list code that it breaks the entire functionality of the generator hub page.
That is, until I recently quickly hatched a simple solution to fix it before going to update the generator statistics for this week. I replaced the use of
let itovar iin some of the code of the HTML panel, and it worked fine again! (I've just learned the difference between them btw)The reason it was left broken and wasn't fixed immediately is that I just haven't had time to fix it due to, as usual, the post-recovery business. (Although I might plan to go back to Perchance slowly and regenerate my spirits to release some new projects and stuff here on this community! 😄)
-
Quem 2.5 (State-of-the-art chatbot) was just released
Link : https://huggingface.co/spaces/Qwen/Qwen2.5
Background (posted today!) : https://qwenlm.github.io/blog/qwen2.5-llm/
//----//
These were released today.
I have 0% knowledge what this thing can do, other than it seems be a really good LLM.
-
New dedicated repo for my notebooks
Link : https://huggingface.co/datasets/codeShare/text-to-image-prompts/tree/main/Google%20Colab%20Notebooks
Still have a ton of data I need to process and upload.
-
I have finally uncovered the secrets of Moloch
I made this page to tell people the story of the Ancient Gods, and Moloch: https://perchance.org/omni-reality
-
indexed text_encoding converter.ipynb + sneak preview
Setting up some proper infrastructure to move the perchance sets onto Huggingface with text_encodings.
This post is a developer diary , kind of. Its gonna be a bit haphazard, but that's the way things are before I get the huggingface gradio module up and running.
The NND method is described here , in this paper which presents various ways to improve CLIP Interrogators: https://arxiv.org/pdf/2303.03032
Easier to just use the notebook then follow this gibberish. We pre-encode a bunch of prompt items , then select the most similiar one using dot product. Thats the TLDR.
I'll try to showcase it at some point. But really , I'm mostly building this tool because it is very convenient for myself + a fun challenge to use CLIP.
It's more complicated than the regular CLIP interrogator , but we get a whole bunch of items to select from , and can select exactly "how similiar" we want it to be to the target image/text encoding.
The \{itemA|itemB|itemC\} format is used as this will select an item at random when used on the perchance text-to-image servers: https://perchance.org/fusion-ai-image-generator
It is also a build-in random selection feature on ComfyUI , coincidentally :
Source : https://blenderneko.github.io/ComfyUI-docs/Interface/Textprompts/#up-and-down-weighting
Links/Resources posted here might be useful to someone in the meantime.
You can find tons of strange modules on the Huggingface page : https://huggingface.co/spaces
For now you will have to make do with the NND CLIP Interrogator notebook : https://huggingface.co/codeShare/JupyterNotebooks/blob/main/sd_token_similarity_calculator.ipynb
text_encoding_converter (also in the NND notebook) : https://huggingface.co/codeShare/JupyterNotebooks/blob/main/indexed_text_encoding_converter.ipynb
I'm using this to batch process JSON files into json + text_encoding paired files. Really useful (for me at least) when building the interrogator. Runs on the either Colab GPU or on Kaggle for added speed: https://www.kaggle.com/
Here is the dataset folder https://huggingface.co/datasets/codeShare/text-to-image-prompts:
Inside these folders you can see the auto-generated safetensor + json pairings in the "text" and "text_encodings" folders.
The JSON file(s) of prompt items from which these were processed are in the "raw" folder.
The text_encodings are stored as safetensors. These all represent 100K female first names , with 1K items in each file.
By splitting the files this way , it uses way less RAM / VRAM as lists of 1K can be processed one at a time.
//-----//
Had some issues earlier with IDs not matching their embeddings but that should be resolved with this new established method I'm using. The hardest part is always getting the infrastructure in place.
I can process roughly 50K text encodings in about the time it takes to write this post (currently processing a set of 100K female firstnames into text encodings for the NND CLIP interrogator. )
EDIT : Here is the output uploaded https://huggingface.co/datasets/codeShare/text-to-image-prompts/tree/main/names/firstnames
I've updated the notebook to include a similarity search for ~100K female firstnames , 100K lastnames and a randomized 36K mix of female firstnames + lastnames
Sources for firstnames : https://huggingface.co/datasets/jbrazzy/baby_names
List of most popular names given to people in the US by year
Sources for lastnames : https://github.com/Debdut/names.io
An international list of all firstnames + lastnames in existance, pretty much . Kinda borked as it is biased towards non-western names. Haven't been able to filter this by nationality unfortunately.
//------//
Its a JSON + safetensor pairing with 1K items in each. Inside the JSON is the name of the .safetensor files which it corresponds to. This system is super quick :)!
I plan on running a list of celebrities against the randomized list for firstnames + lastnames in order to create a list of fake "celebrities" that only exist in Stable Diffusion latent space.
An "ethical" celebrity list, if you can call it that which have similiar text-encodings to real people but are not actually real names.
I have plans on making the NND image interrogator a public resource on Huggingface later down the line, using these sets. Will likely use the repo for perchance imports as well: https://huggingface.co/datasets/codeShare/text-to-image-prompts
-
Huggingface repo created for fusion-gen prompts
Link: https://huggingface.co/datasets/codeShare/text-to-image-prompts/blob/main/README.md
Will update with JSON + text_encoding pairs as I process the sub_generators
-
The contents of the fusion-gen sub-generators can now be downloaded as JSON files
I plan on making my prompt library more accessible.
I'm adding this feature because I plan to build a Huggingface JSON repo of the contents of my sub-generators , which I plan to use for my image interrogator: https://huggingface.co/codeShare/JupyterNotebooks/blob/main/sd_token_similarity_calculator.ipynb
Example: https://perchance.org/fusion-t2i-prompt-features-5
List of currently updated generators can be found here: https://lemmy.world/post/19398527
-
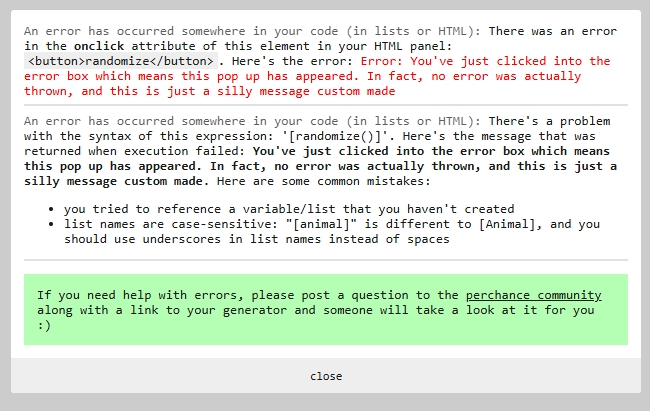
Silly Error
Jokes aside, when I was playing with the markov name generator plugin example, I've discovered another way to throw custom errors, this way through a custom message that would appear as a "syntax error".
There's also a way to throw more customizable errors shown on this post: https://lemmy.world/post/17746310
Oh, and here are more of these custom errors but in different appearances:
-
Token similarity % calculator
Coded it myself in Google Colab. Quite cool if I say so myself
Link: https://huggingface.co/codeShare/JupyterNotebooks/blob/main/sd_token_similarity_calculator.ipynb
-
Adcom's resource links for T2i prompts + other cool stuff
Will update this post with links of stuff I have from the "# cool-finds" on the fusion gen discord: https://discord.gg/exBKyyrbtG
I use that space to yeet links that might be useful. I will try to organize the links here a few items at a time.
//---//
Cover image prompt "\[ #FTSA# : "These are real in long pleated skirt and bangs standing in ruined city Monegasque by ilya kushinova they are all parc. Pretty cute , huh? (leigh cartoon dari courtney-anime wrath art style :0.3) green crowded mountains and roots unique visual effect intricate futuristic hair behind ear hyper realistic5 angry evil : 0.1\] "
//----//
Prompt syntax
Perchance prompt syntax: https://perchance.org/prompt-guide
A111 wiki : https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
Prompt parser.py : https://github.com/AUTOMATIC1111/stable-diffusion-webui/blob/master/modules/prompt_parser.py
Image Interrogators
Converts an image to a prompt
Pharmapsychotic (most popular one) : https://huggingface.co/spaces/pharmapsychotic/CLIP-Interrogator
Danbooru tags : https://huggingface.co/spaces/hysts/DeepDanbooru
How Stable Diffusion prompts works
Just good, technical source material on the "prompt text" => image output works.
https://huggingface.co/docs/diffusers/main/en/using-diffusers/weighted_prompts
https://arxiv.org/abs/2406.02965
This video explains cross-attention : https://youtu.be/sFztPP9qPRc?si=jhoupp4rPfJshj8V
Sampler guide: https://stablediffusionweb.com/blog/stable-diffusion-samplers:-a-comprehensive-guide
AI chat
Audio SFX/ voice lines :
https://www.sounds-resource.com/
https://youtube.com/@soundmefreelyyt?si=yjUPqUVJA7JmUXQC
Lorebooks : https://www.chub.ai/
Online Tokenizer
https://sd-tokenizer.rocker.boo/
The Civitai prompt set
In a separate category because of how useful it is.
The best/largest set of prompts for SD that can be found online , assuming you can find a way to filter out all the "garbage" prompts. Has a lot if NSFW items.
https://huggingface.co/datasets/AdamCodd/Civitai-8m-prompts
The set is massive so I advice using Google colab to avoid filling up your entire harddrive with the .txt documents
I've split a part of the set into more managable 500MB chunks for text processing : https://huggingface.co/codeShare/JupyterNotebooks/tree/main
Prompt Styles
People who have crammed different artists / styles into SD 1.5 and/or SDXL and made a list of what "sticks" , and writtend the results in lists.
https://lightroom.adobe.com/shares/e02b386129f444a7ab420cb28798c6b6 https://cheatsheet.strea.ly/
https://github.com/proximasan/sdxl_artist_styles_studies
https://huggingface.co/spaces/terrariyum/SDXL-artists-browser
https://docs.google.com/spreadsheets/d/1_jgQ9SyvUaBNP1mHHEzZ6HhL_Es1KwBKQtnpnmWW82I/htmlview#gid=1637207356
https://weirdwonderfulai.art/resources/stable-diffusion-xl-sdxl-art-medium/
https://rikkar69.github.io/SDXL-artist-study/
https://medium.com/@soapsudtycoon/stable-diffusion-trending-on-art-station-and-other-myths-c09b09084e33
https://docs.google.com/spreadsheets/u/0/d/1SRqJ7F_6yHVSOeCi3U82aA448TqEGrUlRrLLZ51abLg/htmlview
https://stable-diffusion-art.com/illustrated-guide/
https://rentry.org/artists_sd-v1-4
https://aiartes.com/
https://stablediffusion.fr/artists
https://proximacentaurib.notion.site/e28a4f8d97724f14a784a538b8589e7d?v=42948fd8f45c4d47a0edfc4b78937474
https://sdxl.parrotzone.art/
https://www.shruggingface.com/blog/blending-artist-styles-together-with-stable-diffusion-and-lora
3 Rules of prompting
-
There is no correct way to prompt.
-
Stable diffusion reads your prompt left to right, one token at a time, finding association from the previous token to the current token and to the image generated thus far (Cross Attention Rule)
-
Stable Diffusion is an optimization problem that seeks to maximize similarity to prompt and minimize similarity to negatives (Optimization Rule)
The SD pipeline
For every step (20 in total by default) :
- Prompt text => (tokenizer)
- => Nx768 token vectors =>(CLIP model) =>
- 1x768 encoding => ( the SD model / Unet ) =>
- => Desired image per Rule 3 => ( sampler)
- => Paint a section of the image => (image)
Latent space properties
Weights for token A = assigns magnitude value to be multiplied with the 1x768 token vector A. By default 1.
Direction of token A = The theta angle between tokens A and B is equivalent to similarity between A and B. Calculated as the normalized dot product between A and B (cosine similarity).
CLIP properties (used in SD 1.5 , SDXL and FLUX)
The vocab.json = a list of 47K tokens of fixed value which corresponds to english words , or fragments of english words.
ID of token A = the lower the ID , the more "fungible" A is in the prompt.
The higher the ID , the more "niche" the training data for token A will be
Perchance sub-generators (text-to-image)
The following generators contain prompt items which you may use for your own T2i projects. These ones are recently updated to allow you to download their contents as a JSON file. I'm writing these here to keep track of generator that are updated vs. non-updated.
For the full list of available datasets , scroll through the code on the fusion gen :
https://perchance.org/fusion-ai-image-generator
//---//
https://perchance.org/fusion-t2i-prompt-features-1
https://perchance.org/fusion-t2i-prompt-features-2
https://perchance.org/fusion-t2i-prompt-features-3
https://perchance.org/fusion-t2i-prompt-features-4
https://perchance.org/fusion-t2i-prompt-features-5
https://perchance.org/fusion-t2i-prompt-features-6
https://perchance.org/fusion-t2i-prompt-features-7
https://perchance.org/fusion-t2i-prompt-features-8
https://perchance.org/fusion-t2i-prompt-features-9
https://perchance.org/fusion-t2i-prompt-features-10
https://perchance.org/fusion-t2i-prompt-features-11
https://perchance.org/fusion-t2i-prompt-features-12
https://perchance.org/fusion-t2i-prompt-features-13
https://perchance.org/fusion-t2i-prompt-features-14
https://perchance.org/fusion-t2i-prompt-features-15
https://perchance.org/fusion-t2i-prompt-features-16
https://perchance.org/fusion-t2i-prompt-features-17
https://perchance.org/fusion-t2i-prompt-features-18
https://perchance.org/fusion-t2i-prompt-features-19
https://perchance.org/fusion-t2i-prompt-features-20 (copy of fusion-t2i-prompt-features-1)
https://perchance.org/fusion-t2i-prompt-features-21
https://perchance.org/fusion-t2i-prompt-features-22
https://perchance.org/fusion-t2i-prompt-features-23
https://perchance.org/fusion-t2i-prompt-features-24
https://perchance.org/fusion-t2i-prompt-features-25
https://perchance.org/fusion-t2i-prompt-features-26
https://perchance.org/fusion-t2i-prompt-features-27
https://perchance.org/fusion-t2i-prompt-features-28
https://perchance.org/fusion-t2i-prompt-features-29
https://perchance.org/fusion-t2i-prompt-features-30
https://perchance.org/fusion-t2i-prompt-features-31
https://perchance.org/fusion-t2i-prompt-features-32
https://perchance.org/fusion-t2i-prompt-features-33
https://perchance.org/fusion-t2i-prompt-features-34
//----//
-
-
Sen. Scott Weiner (D.) Bloomberg interview on his proposed SB-1047 bill to enable Silicon Valley to pro-actively 'regulate harmful AI generated content'
Bloomberg interview: https://youtu.be/tZCAvME-a98?si=OTcjxhE8iJfdo_lU
This is California San Francisco , "the hub" of all the major tech giants.
SB 1047 ('restrict commercial use of harmful AI models in California') partisan bill (Democrat 4-0) proposed by San Francisco senator Scott Weiner : https://legiscan.com/CA/text/SB1047/2023
-
The 'AI Generated Watermark Bill' AB3211 expanded with added clauses , placed on hold until further review
Source:https://legiscan.com/CA/text/AB3211/id/2984195
Clarifications
(l) “Provenance data” means data that identifies the origins of synthetic content, including, but not limited to, the following:
(1) The name of the generative AI provider.
(2) The name and version number of the AI system that generated the content.
(3) The time and date of the creation.
(4) The portions of content that are synthetic.
(m) “Synthetic content” means information, including images, videos, audio, and text, that has been produced or significantly modified by a generative AI system.
(n) “Watermark” means information that is embedded into a generative AI system’s output for the purpose of conveying its synthetic nature, identity, provenance, history of modifications, or history of conveyance.
(o) “Watermark decoders” means freely available software tools or online services that can read or interpret watermarks and output the provenance data embedded in them.
AI Generative services obligations
(a) A generative AI provider shall do all of the following:
(1) Place imperceptible and maximally indelible watermarks containing provenance data into synthetic content produced or significantly modified by a generative AI system that the provider makes available.
(A) If a sample of synthetic content is too small to contain the required provenance data, the provider shall, at minimum, attempt to embed watermarking information that identifies the content as synthetic and provide the following provenance information in order of priority, with clause (i) being the most important, and clause (iv) being the least important:
(i) The name of the generative AI provider.
(ii) The name and version number of the AI system that generated the content.
(iii) The time and date of the creation of the content.
(iv) If applicable, the specific portions of the content that are synthetic.
Use of watermarks
(B) To the greatest extent possible, watermarks shall be designed to retain information that identifies content as synthetic and gives the name of the provider in the event that a sample of synthetic content is corrupted, downscaled, cropped, or otherwise damaged.
(2) Develop downloadable watermark decoders that allow a user to determine whether a piece of content was created with the provider’s system, and make those tools available to the public.
(A) The watermark decoders shall be easy to use by individuals seeking to quickly assess the provenance of a single piece of content.
(B) The watermark decoders shall adhere, to the greatest extent possible, to relevant national or international standards.
(3) Conduct AI red-teaming exercises involving third-party experts to test whether watermarks can be easily removed from synthetic content produced by the provider’s generative AI systems, as well as whether the provider’s generative AI systems can be used to falsely add watermarks to otherwise authentic content. Red-teaming exercises shall be conducted before the release of any new generative AI system and annually thereafter.
(b) A generative AI provider may continue to make available a generative AI system that was made available before the date upon which this act takes effect and that does not have watermarking capabilities as described by paragraph (1) of subdivision (a), if either of the following conditions are met:
(1) The provider is able to retroactively create and make publicly available a decoder that accurately determines whether a given piece of content was produced by the provider’s system with at least 99 percent accuracy as measured by an independent auditor.
(c) Providers and distributors of software and online services shall not make available a system, application, tool, or service that is designed to remove watermarks from synthetic content.
(d) Generative AI hosting platforms shall not make available a generative AI system that does not place maximally indelible watermarks containing provenance data into content created by the system.
AI Text Chat LLMs
(f) (1) A conversational AI system shall clearly and prominently disclose to users that the conversational AI system generates synthetic content.
(A) In visual interfaces, including, but not limited to, text chats or video calling, a conversational AI system shall place the disclosure required under this subdivision in the interface itself and maintain the disclosure’s visibility in a prominent location throughout any interaction with the interface.
(B) In audio-only interfaces, including, but not limited to, phone or other voice calling systems, a conversational AI system shall verbally make the disclosure required under this subdivision at the beginning and end of a call.
(2) In all conversational interfaces of a conversational AI system, the conversational AI system shall, at the beginning of a user’s interaction with the system, obtain a user’s affirmative consent acknowledging that the user has been informed that they are interacting with a conversational AI system. A conversational AI system shall obtain a user’s affirmative consent prior to beginning the conversation.
(4) The requirements under this subdivision shall not apply to conversational AI systems that do not produce inauthentic content.
'Add Authenticity watermark to all cameras'
(a) For purposes of this section, the following definitions apply:
(1) “Authenticity watermark” means a watermark of authentic content that includes the name of the device manufacturer.
(2) “Camera and recording device manufacturer” means the makers of a device that can record photographic, audio, or video content, including, but not limited to, video and still photography cameras, mobile phones with built-in cameras or microphones, and voice recorders.
(3) “Provenance watermark” means a watermark of authentic content that includes details about the content, including, but not limited to, the time and date of production, the name of the user, details about the device, and a digital signature.
(b) (1) Beginning January 1, 2026, newly manufactured digital cameras and recording devices sold, offered for sale, or distributed in California shall offer users the option to place an authenticity watermark and provenance watermark in the content produced by that device.
(2) A user shall have the option to remove the authenticity and provenance watermarks from the content produced by their device.
(3) Authenticity watermarks shall be turned on by default, while provenance watermarks shall be turned off by default.
How to demonstrate use
Beginning March 1, 2025, a large online platform shall use labels to prominently disclose the provenance data found in watermarks or digital signatures in content distributed to users on its platforms.
(1) The labels shall indicate whether content is fully synthetic, partially synthetic, authentic, authentic with minor modifications, or does not contain a watermark.
(2) A user shall be able to click or tap on a label to inspect provenance data in an easy-to-understand format.
(b) The disclosure required under subdivision (a) shall be readily legible to an average viewer or, if the content is in audio format, shall be clearly audible. A disclosure in audio content shall occur at the beginning and end of a piece of content and shall be presented in a prominent manner and at a comparable volume and speaking cadence as other spoken words in the content. A disclosure in video content should be legible for the full duration of the video.
(c) A large online platform shall use state-of-the-art techniques to detect and label synthetic content that has had watermarks removed or that was produced by generative AI systems without watermarking functionality.
(d) (1) A large online platform shall require a user that uploads or distributes content on its platform to disclose whether the content is synthetic content.
(2) A large online platform shall include prominent warnings to users that uploading or distributing synthetic content without disclosing that it is synthetic content may result in disciplinary action.
(e) A large online platform shall use state-of-the-art techniques to detect and label text-based inauthentic content that is uploaded by users.
(f) A large online platform shall make accessible a verification process for users to apply a digital signature to authentic content. The verification process shall include options that do not require disclosure of personal identifiable information.
'AI services must reports their efforts against harmful content'
(a) (1) Beginning January 1, 2026, and annually thereafter, generative AI providers and large online platforms shall produce a Risk Assessment and Mitigation Report that assesses the risks posed and harms caused by synthetic content generated by their systems or hosted on their platforms.
(2) The report shall include, but not be limited to, assessments of the distribution of AI-generated child sexual abuse materials, nonconsensual intimate imagery, disinformation related to elections or public health, plagiarism, or other instances where synthetic or inauthentic content caused or may have the potential to cause harm.
Penalty for violating this bill
A violation of this chapter may result in an administrative penalty, assessed by the Department of Technology, of up to one million dollars ($1,000,000) or 5 percent of the violator’s annual global revenue, whichever is higher
-
Ai Image Challenge for September ~ Concrete Jungle (ended)
Ai Image Challenge for September ~ Concrete Jungle
When:
September 3, 2024 12:00PM UTCtoSeptember 30, 2024 12:00PM UTCWelcome one and all to the Monthly Image Challenge. This month's topic is 'Concrete Jungle'. One image only please!
Use a Perchance image generator to generate up some SFW images on the topic. Find one you like, and post it as a comment in the post. One Entry per person. While you are here, upvote the ones you like. Everyone wins of course, but whoever gets the most upvotes 'extrawins' and gets to choose the topic for next month. So come make and share something!
Perchance Data
```perchance_data // This Part is Required for the Perchance Hub // This would be where the Event Organizer would change the data to update the Hub // Remember to indent with two spaces!
// List About the Event to be displayed on the Hub metadata title = Ai Image Challenge for September ~ Concrete Jungle description = Hit Go To Post, Drop an image, generated with Perchance, in the comments and upvote the ones you like. type = Image Challenge image https://lemmy.world/pictrs/image/3f9e5cc3-b797-4408-81a7-99e0a7f8269e.png // Can be multiple pictures to randomize the banner image :) start = 3 September 2024 00:12:00 UTC+0000 // strict data formats see: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/parse#non-standard_date_strings end = 30 September 2024 00:12:00 UTC+0000 color = linear-gradient(45deg, #66ff8f 33%, #4625a8, #25a846 95%) rules = Comment an image on the topic and upvote ones you like. Winner of the month gets to choose next month's topic.
// For Generator Jams with Perchance URL generators // The generator's $metadata is also parsed images https://lemmy.world/pictrs/image/927070e1-947d-465c-bb02-a02cea26cfc0.png author = VioneT description = Futuristic Brutalist Architecture + Times Square https://lemmy.world/pictrs/image/d191d416-3223-4036-ab1a-b89d0daef705.jpeg author = Allo description = remnant https://sh.itjust.works/pictrs/image/19523811-3fa8-4ff8-81f7-bbb6ea30dd56.png author = BluePower description = The Glowing Subcity of Trotopia https://lemmy.world/pictrs/image/046caa84-c67a-450a-9887-8a01239e9139.jpeg author = s10dayhobby description = Lush Concrete Jungle ```
previous winners:
-
Improved YT playlist to MP3 (For all your music needs)
Old version was trash, so I made update where you can just print a Youtube playlist link to get all videos as MP3:s
https://huggingface.co/codeShare/JupyterNotebooks/blob/main/YT-playlist-to-mp3.ipynb
Very useful tool for me , so I'm posting it here to share.
-
A question about Ai chat(role playing one)
I waa confused and scared especially after hearing what's going on with c.ai that staff can read your chats or control the bot,so i wanted to ask,does this one also do that or collect your data in chats? Like is there someone who can read my chats?
-
This has been my favorite part of my experiment page for a while :)
I made a "mini name generator" section in my view counter experiment page several days ago, displaying generated names consisting of mixed sets of words and names using the beautiful markov name generator plugin and I've been liking the results so far.
Also, could be some sort of teaser for the future name forms in my name generator in a future update! 😉
-
The official SD 1.5 model just got deleted off huggingface 😱
(Non-existant) link : https://huggingface.co/runwayml/stable-diffusion-v1-5
There is no longer an offical version of SD 1.5!
RunwayML has basically disavowed any involvement with the original Stable Diffusion Model.
If I had to guess reasons , I'd say it's a pro-active measure against potential future litigation.
Might even be connected to recent developments in California: https://lemmy.world/post/19258795
Pure speculation of course. I really have no idea.
Still, it's a pretty shocking decision given the popularity of the SD 1.5 model.
-
California bill to 'force provence on AI generated content' and restrict 'harmful AI models' from commercial use
Bill SB 1047 ('restrict commercial use of harmful AI models in California') :https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=202320240SB1047
Bill AB 3211 ('AI generation services must include tamper-proof watermarks on all AI generated content') : https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=202320240AB3211
Image is Senator Scott Wiener (Democrat) , who put forward this bill.
//----//
SB 1047 is written like the California senators think AI-generated models are Skynet or something.
Quotes from SB 1047:
"This bill .... requires that a developer, before beginning to initially train a covered model, as defined, comply with various requirements, including implementing the capability to promptly enact a full shutdown, as defined, and implement a written and separate safety and security protocol, as specified."
"c) If not properly subject to human controls, future development in artificial intelligence may also have the potential to be used to create novel threats to public safety and security, including by enabling the creation and the proliferation of weapons of mass destruction, such as biological, chemical, and nuclear weapons, as well as weapons with cyber-offensive capabilities."
Additionally , SB 1047 is written so that California senators can dictate what AI models is "ok to train" and which "are not ok to train".
Or put more plainly; "AI models that adhere to California politics" vs. "Everything else".
Legislative "Woke bias" for AI-models , essentially.
//----//
AB 3211 has a more grounded approach , focusing on how AI generated content can potentially be used for online disinformation.
The AB 3211 bill says that all AI generation services must have watermarks that can identify the content as being produced by an AI-tool.
I don't know of any examples of AI being used for political disinformation yet (have you?).
Though seeing the latest Flux model I realize it is becoming really hard to tell the difference between an AI generated image and a real stockphoto.
The AB 3211 is frustratingly vague with regards to proving an image is AI generated vs. respecting user privacy.
Quotes from AB 3211:
"This bill, the California Digital Content Provenance Standards, would require a generative artificial intelligence (AI) provider, as provided, to, among other things, apply provenance data to synthetic content produced or significantly modified by a generative AI system that the provider makes available, as those terms are defined, and to conduct adversarial testing exercises, as prescribed."
The bill does not specify what method(s) should be used to provide 'Providence'.
But practically speaking for present-day AI image generation sites, this refers to either adding extra text to the metadata , or by subtly encoding text into the image by modifying the RGB values of the pixels in the image itself.
This latter as known as a "invisible watermark": https://www.locklizard.com/document-security-blog/invisible-watermarks/
The AB 3211 explicitly states that the 'Providence' must be tamper proof.
This is strange, since any aspect of a .png or .mp3 file can be modified at will.
It seems legislators of this bill has no clue what they are talking about here.
Depending on how one wishes to interpret the AB 3211 bill , this encoding can include any other bits of information as well; such as the IP adress of the user , the prompt used for the image and the exact date the image was generated.
Any watermarking added to a public image that includes private user data will be in violation of EU-law.
That being said , expect a new "Terms of Service" on AI generation site in response to this new bill.
Read the terms carefully. There might be a watermark update on generated images , or there might not.
Watermarks on RGB values of generated images can easily be removed by resizing the image in MS paint , or by taking a screenshot of the image.
Articles:
SB1047: https://techcrunch.com/2024/08/30/california-ai-bill-sb-1047-aims-to-prevent-ai-disasters-but-silicon-valley-warns-it-will-cause-one/
AB3211: https://www.thedrum.com/news/2024/08/28/how-might-advertisers-be-impacted-california-s-new-ai-watermarking-bill
-
David Gottesmann is behind Perchance image generators?
Hello everyone, I recently came across this blog that appears to claims that "David Gottesmann is the man behind the Perchance AI."
Not that I have something against it, but what do you think?
Below is s screenshot from said blog. !
By the way, the blog's main subject appears to offer an alternative to Perchance AI image generator(s), I do wonder why they think the AI part is the whole Perchance.
-
Thought of a clever upgrade for landscapes today.
Had realized over a while that the anime model occasionally made nice pure landscape pics. Like how Anthro has the sideeffect of making good nude anatomy and there's a trick to using the anthro model to generate normal pics but with better anatomy, Anime has the sideeffect of good landscapes. Anyway, this was a realization today that allowed me to upgrade the 'Place' style on Beautiful People. Sharing in case it helps anyone else!
-
The Perchance AI Stable Diffusion generator (fusion-gen) now has a anime tag tool (link in description)
It's very useful. I made this guide to post in the tutorials.
Find Danbooru tags here: https://danbooru.donmai.us/related_tag
(If you know of a better/alternate resource for searching/finding anime tags please post below)
Fusion gen: https://perchance.org/fusion-ai-image-generator
Fusion discord: https://discord.gg/8TVHPf6Edn
//---//
Perchance uses a different text-to-image model based on user input in the prompt.
The "prompt using tags" is a quirk that works for the anime model , and likely the furry model too if using e621 tags.
But "prompt using tags" will not work as well for the photoreal model. Just something to keep in mind.
Recommend you set the base prompt to #COMIC# to guarantee the "anime perchance model" being used.
(EDIT: Also I realize posted stuff into the "Inspect Wildcard" field in for the Legend of Zelda tags. Eh..mistakes happen. )
-
ai-character-chat slowed down
cross-posted from: https://lemmy.world/post/18576236
> Hello! > > For whatever reason, since a few hours ago, the character chat significantly slowed down for me. Usually, it takes just around ten seconds to generate a response, but now it's more than a minute. > > Also, ai-text-to-image-generator at first didn't want to work, saying "Anti-bot verification failed. VPNs may cause this issue" even though I don't use a VPN. Now it works well again, but I wonder whether the issues are related. > > Anyone else experiencing anything similar for either of these or is it just me?
UPD: developer (on the original post) noticed and fixed the issue
-
NEWS I interviewed the founder of Civitai, an AI platform accused of deepfakes and porn. It highlighted the challenges of open source AI.
just found this interesting read https://sharongoldman.substack.com/p/i-interviewed-the-founder-of-civitai
-
New US legislation regarding AI generated NSFW content of real people
https://www.rollingstone.com/politics/politics-news/aoc-deepfake-porn-bill-senate-1235067061/?_bhlid=e6c71ce8cfabf81592c60c363025147eb9c38095
-
Layering with timings
\[top-down view, geometric shapes vibrant coloured, (grass green background:0.2) : : 0.2\] \[ \[ : (city:1.3) : 0.2\] : : 0.6\] \[ : anime, cyberpunk city : 0.6 \] top-downTo explain, the first line uses the prompttop-down view, geometric shapes vibrant coloured, (grass green background:0.2)for the first 20% of steps. The general shapes/colours are established.The second line,
(city:1.3)is the prompt from 20% to 60% of steps. Transformed into a city based on those shapes.The third line,
anime, cyberpunk cityis the prompt from 60% to the end. A layer of style added on top.Outside any of that, the last line
top-downis always tagged onto the end to try to keep the view stable. -
Unexplored Wilderness (Ended)
Unexplored Wilderness
Create generators that invoke the wilderness (nature, danger), curiosity (discovery, documentation), and adventure (heading into the unknown, trailblazing), be it fictional or non-fiction.
Make generators with the lines of an odyssey to unexplored regions, mapping the vast reaches of the galaxy, or looking deep within oneself.
When:
August 7, 2024 12:00PM UTCtoAugust 28, 2024 12:00PM UTCPerchance Data
```perchance_data // This Part is Required for the Perchance Hub // This would be where the Event Organizer would change the data to update the Hub // Remember to indent with two spaces!
// List About the Event to be displayed on the Hub metadata title = Unexplored Wilderness description = Create generators that invoke the wilderness (nature, danger), curiosity (discovery, documentation), and adventure (heading into the unknown, trailblazing), be it fictional or non-fiction. type = Generator Jam image https://lemmy.world/pictrs/image/f3889aca-b153-49a9-a9b0-2079eba7dce3.png // Can be multiple pictures to randomize the banner image :) start = 07 August 2024 12:00:00 UTC+0000 // strict data formats see: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/parse#non-standard_date_strings end = 28 August 2024 12:00:00 UTC+0000 color = linear-gradient(77deg, #386945, #30aa34) rules = Make generators with the lines of an odyssey to unexplored regions, mapping the vast reaches of the galaxy, or looking deep within oneself.
// For Generator Jams with Perchance URL generators // The generator's $metadata is also parsed immerse-in-senses author = Vionet20 type = Text // For Image Events images
// You can request a format of other events just ask on the forum! // Banner Info: // Generator Used: text2image-generator // Prompt: a behind the character shot of a small group on high elevation overlooking an unexplored forest region, exploration, adventure, high fantasy, concept art // Negative Prompt: \[mountains, mountain ranges, high mountains, columns of rocks:0.05\] // Resolution: 768x512 // Art Style: [Vionet20-Styles] Comic/Manga Illustration ```
-
Ai Image Challenge for August ~ Unexpected Crossover or Cold (Ended)
Ai Image Challenge for August ~ Unexpected Crossover or Cold
When:
August 3, 2024 12:00PM UTCtoAugust 31, 2024 12:00PM UTCWelcome one and all to the Monthly Image Challenge. This month's topic is 'Unexpected Crossover (mix franchises) or Cold'. Two possible topics to choose from!
Use a Perchance image generator to generate up some SFW images on the topic. Find one you like, and post it as a comment in the post. One Entry per person. While you are here, upvote the ones you like. Everyone wins of course, but whoever gets the most upvotes 'extrawins' and gets to choose the topic for next month. So come make and share something.
Perchance Data
```perchance_data // This Part is Required for the Perchance Hub // This would be where the Event Organizer would change the data to update the Hub // Remember to indent with two spaces!
// List About the Event to be displayed on the Hub metadata title = Ai Image Challenge for August ~ Unexpected Crossover or Cold description = Hit Go To Post, Drop an image, generated with Perchance, in the comments and upvote the ones you like. type = Image Challenge image https://user-uploads.perchance.org/file/64213c62404f12b5943c8adbdd720592.jpeg // Can be multiple pictures to randomize the banner image :) start = 3 August 2024 00:12:00 UTC+0000 // strict data formats see: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/parse#non-standard_date_strings end = 31 August 2024 00:12:00 UTC+0000 color = linear-gradient(45deg, #66ff8f 33%, #4625a8, #25a846 95%) rules = Comment an image on the topic and upvote ones you like. Winner of the month gets to choose next month's topic.
// For Generator Jams with Perchance URL generators // The generator's $metadata is also parsed images https://lemmy.world/pictrs/image/3cf0717a-ff30-41cb-8387-647125b4d42c.jpeg author = Raven_ description = Gollum X Minions - Not the Crossover that we need, but the one that we deserve. https://sh.itjust.works/pictrs/image/70a471ca-701e-4cab-aec9-8c7a0e5a762e.png author = BluePower description = A winter ski marathon where hundreds of people participate in the competition to get to the top of the breezing mountain. 🏂 https://lemmy.world/pictrs/image/c112ced0-cf4c-41bb-b081-37dd8b51fe23.jpeg author = Allo description = Temple of Galactic Light https://lemmy.world/pictrs/image/26df9b23-cfa6-4844-a2ae-d0422ec99fea.jpeg author = Phantomx description = “Alice in Wonderland” and the futuristic realm of “Tron.” https://lemmy.world/pictrs/image/edaa761b-26ed-4944-a3bb-48b2e5de018c.webp author = Braucher description = Frau Holle, Swiss alps snowy landscape, mature blonde woman standing by water well, germanic goddess https://lemmy.world/pictrs/image/c7842ab0-1b8b-4522-a7f3-892cfa708b46.jpeg author = Vovanella description = mysterios ancient ice city, ice shards https://lemmy.world/pictrs/image/b80704de-36b3-4bec-bcee-d900ff74f76b.png author = VioneT description = A colossal crystalline structure in deep space. It resembles the shape of an anchor and is estimated to be about 334 solar radii in width and double in height. The origins of it are unknown and is first discovered by a deep space probe 133 light years from planet SSA-763. Material composition tests suggest that it is an asymmetric lattice of an unknown composition, but the temperature of it is constantly zero degrees Celsius. https://lemmy.world/pictrs/image/593a5322-8f98-441a-b04f-e7ce08948d8d.jpeg author = Samalamilam description = icy, snowy Japanese style back alley, little child girl sitting to the right against a building, breathing into her hands to warm up her cold hands, small kitsune girl, fox features, fox furry, super fluffy, focal point is down at the end of the alley while the girl is off to the side, snowfall, cinematic shot, super high detail, cold, cinematic shot, dynamic lighting, Technicolor, Panavision, cinemascope, sharp focus, fine details, 8k, HDR, realism, realistic, key visual, film still, cinematic color grading, depth of field, (anthro:0.1), far away zoomed in shot, small child, baggy clothing, picture taken from far away, little girl not looking at camera, super cute, adorable little girl, super fluffy fur, makes you feel empathy, facing to the left, hands up to her mouth, middle ground to background focus, sitting on her butt in fetal position, leaning against the building, sad expression, hands up to her mouth, breathing vapor onto her hands, cold, furry, anthro fox child ```
previous winners:
-
Finished-First Text-to-Image Plugin
I don't know if you're interested in plugins here, but... here's a plugin I made: https://perchance.org/finished-first-text-to-image-plugin
Uses the regular image generator plugin, but adds 2 features: re-ordering finished generations so they appear to complete "in order". This is something I've thought about for a while when using existing image generators on Perchance. This way, there's no need to scroll back and forth looking for completed images; they all just jump the queue to show themselves.
And a
countargument to easily generate many images at once. This is a very common feature image generators use on Perchance, but more code (and therefore understanding of code) is needed to make that work. This just simplifies it a touch, is all. -
Latest BluePower news
So I've been inactive for a full week, but at least I'm back here for now! There are some serious things I want to talk about just to keep your eyes out on the generator updating journey, especially with the ongoing huge 2.0.20.1 Generator Manager update development.
Last week I've just experienced one of the most devastating events of my entire journey with my personal device I usually use to work on the managing and updating generators and also off-Perchance side projects. A big incident happened where my personal device somehow got blue-screened for a while and then after turning it back on, after a while, it just bricked up and stopped working while I was working on the Preview update (coincidentally with the mass worldwide Windows outage that happened at the time) and had to be repaired for several days. I wasn't able to do much other than constantly checking and updating the generator hub page on mobile during that time.
Sadly, all the data inside was lost for good, and was pretty much unrecoverable, including all the off-Perchance side projects that I've been working for many days on. I then became disappointed and demotivated for a while knowing all the data on the old hard drive on the device was lost due to the event.
That's when I decided to spend most of my time with the repaired device to restore and rebuild everything to a state used to be before it was lost, even though it'll not be exactly 100%. And that's where I'm going to spend most of the time doing that, going onto the big recovery business, using most of my mind on rebuilding all the side projects I've ever spent my time on and doing other important stuff for a couple weeks.
Luckily enough, I've already backed up my unfinished Generator Manager update code, so I don't have to struggle re-writing each of the lines ever again! I've also backed up some of the raw files for the generator trailers, so I don't have to create the trailers from scratch. But once everything's back to normal again, I can finally spend more time exploring some good stuff on Perchance and continue working on the huge 2.0.20.1 update (I'll be posting a new trailer once I'm ready for that).
But don't worry, I'll not going to fully go out of Perchance, I'll still be revisiting the site whenever I wanted to. And see the moments my generator hub page reaching 30.0k views and congratulating it, speaking of which, I'll be planning something else for the milestone... (here's a progress bar for now!)
So that's all I have to say! I hope this goes well and quick enough that I can start working on the Preview update again in no time. 😌
Bonus question: Has everything changed on Perchance recently during my full-week break? I've wanted to check actually, but I was too lazy to do it because of the business.
-
How to generate multycolored hair.
I'm tring to generate jackal girl with haircolor of an actual jackal but can't figure out a way to do it. I tried writhing "two colored hair, dark grey roots, redish brown tips/ends" "dark grey hair transitioning/changing into redish brown" "multycolored hair" with specific colors afterwards "orange hair with grey hair roots" "gray hair with orange hair tips" tried using terms form this article etc. but nothing seems to work. Any ideas?
-
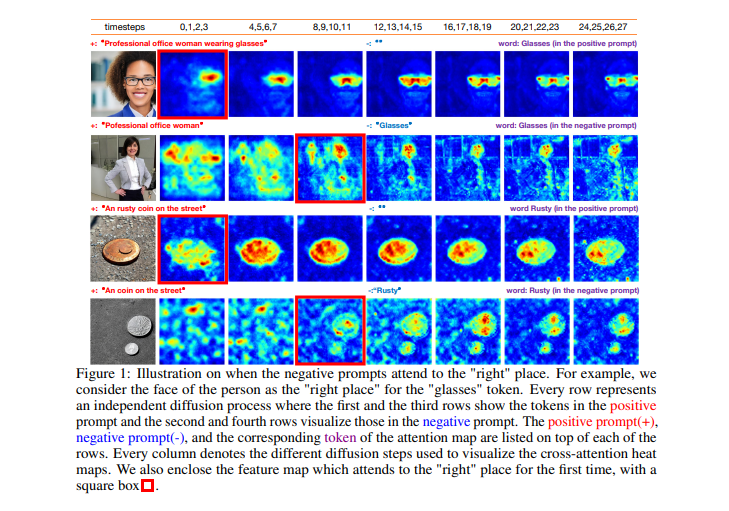
Negatives are flawed
People need to know this more so Imma post it here: https://arxiv.org/abs/2406.02965
TLDR;
If you write "A B C" in your negatives
To prevent this flaw , Write your negatives with delay
e.g
\\[ : A B C : 0.6\\]
(this will enable the negatives after 60% of the generation steps. You can set some other value instead of 0.6 )
You can set some other value than 0.6.
To eliminate stuff 100% the paper recommends using values between 0.2 and 0.3 .
What is the flaw?
Applying negatives to pure noise in early generation well "render" the negatives to the image
It takes a few seconds to add to the prompt, but will help output immensely. Just good stuff to know.
The fusion generator has this feature by default so you can run your favourite prompts there to compare results: https://perchance.org/fusion-ai-image-generator
-
Trying to avoid one of the "auto-art styles"
Ok, so. When using perchance AI generators (mostly this one) with art style set to "Anime" and no extra specifications in prompt, I usualy get results in style of the bottom row and for a most part that is one I preffer. but with some prompts (in this case any mention of dragongirl) I get the top row art style which while not horrible I just find less apealing. Not to mention some of the abominations it generates when I use any of the "add style" options. Is there any way to force the AI to generate in bottom row style or not to in the top one please? I know this is probably stupid request but I just really want to avoid that style.
Thank you in advance for any help.
-
/much-audio// how to create a songplaylist ?
i like the much-audio plug, but i would like to create a playlist to control wich tracks will be played first. at the moment i can only edit when i take songs out or mark them with the comment slashys //. any help ?...sry im new to this
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}