Archive.org has an extension that automatically downloads web pages you visit
Archive.org has an extension that automatically downloads web pages you visit
https://chrome.google.com/webstore/detail/wayback-machine/fpnmgdkabkmnadcjpehmlllkndpkmiak
https://addons.mozilla.org/en-CA/firefox/addon/wayback-machine_new/
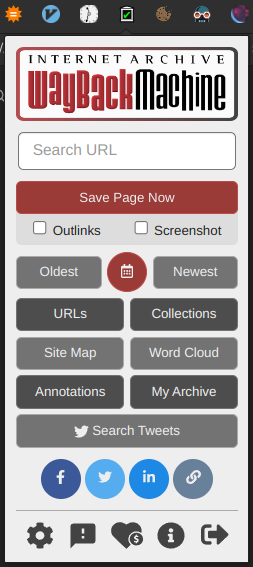
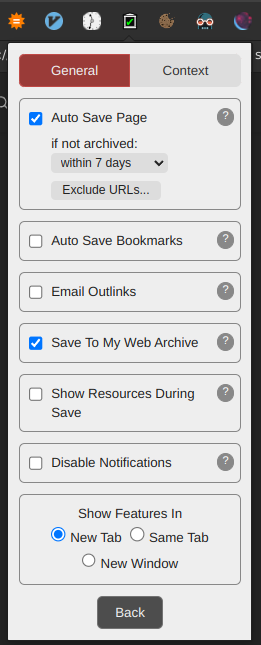
It will also detect when a webpage you are trying to visit is dead and will offer to replay an archived version
You're viewing a single thread.
Is this just for personal purposes or would I be contributing to the internet archive?
Purely to contribute to the internet archive. There’s the “save page now” button that’ll save the webpage to your account, but the automatic downloader that I refer to in the post doesn’t do that and is purely for the sake of expanding the archive.
How safe is it to have automatic page saving enabled when using websites that require an account? Can it potentially dox oneself?
it doesn't literally scrape the web page off your browser, it just sends a download request to the internet archive to download the webpage associated with the URL that you're visiting
-replying from kbin because lemmy just wouldn't let me reply... I'd been trying for over 20 minutes.
I wasn't sure if it was using the client to capture the snapshot or not, better safe than sorry! Thanks for explaining.
The I'll definitely be doing this. Happy to contribute to the archive, especially because it came in clutch during the other site's blackout. Digital preservation is not supported enough