Lemmy Server Performance
-
Redis, Memcached, dragonfly for Lemmy and 2010 presentation on scaling....
Lemmy is incredibly unique in it's stance of not using Redis, Memcached, dragonfly... something. And all the CPU cores and RAM for what this week is reported as 57K active users across over 1200 Instance servers.
Why no Redis, Memcached, dragonfly? These are staples of API for scaling.
Anyway, Reddit too started with PostgreSQL and was open source.
MONDAY, MAY 17, 2010
http://highscalability.com/blog/2010/5/17/7-lessons-learned-while-building-reddit-to-270-million-page.html
"and growing Reddit to 7.5 million users per month"
Lesson 5: Memcache The essence of this lesson is: memcache everything.
They store everything in memcache: 1. Database data 2. Session data 3. Rendered pages 4. Memoizing (remember previously calculated results) internal functions 5. Rate-limiting user actions, crawlers 6. Storing pre-computing listings/pages 7. Global locking.
They store more data now in Memcachedb than Postgres. It’s like memcache but stores to disk. Very fast. All queries are generated by same piece of control and is cached in memcached. Change password Links and associated state are cached for 20 minutes or so. Same for Captchas. Used for links they don’t want to store forever.
They built memoization into their framework. Results that are calculated are also cached: normalized pages, listings, everything.
-
lemmy Server Performance backwards from PostgreSQL data to Rust code and TRIGGER FUNCTION logic, listed observations
-
post primary key has gaps in it, the sequence is being used for transactions that are later canceled or some kind of orphan posts? This is observable from incoming federation posts from other instances.
-
comment_aggregates has a unique id column from comment table id column. There is a one to one row relationship. Can the logic be reworked to eliminate the extra column and related INDEX overhead?
-
Related to 2... Same issue probably exist in post_aggregates table and others that have one to one join relationships.
-
-
Lemmy Server Performance, PostgreSQL log_min_duration_statement - can big servers share logs? value 2500ms targeting "slow queries"
This is the first post or comment in Lemmy history to say log_min_duration_statement ... ;)
It is possible to instruct PostgreSQL to log any query that takes over a certain amount of time, 2.5 seconds what I think would be a useful starting point. Minimizing the amount of logging activity to only those causing the most serious issues.
"Possibly the most generally useful log setting for troubleshooting performance, especially on a production server. Records only long-running queries for analysis; since these are often your "problem" queries, these are the most useful ones to know about. Used for pg_fouine." - https://postgresqlco.nf/doc/en/param/log_min_duration_statement/
I think it would really help if we could get lemmy.world or some other big site to turn on this logging and share it so we can try to better reproduce the performance overloads on development/testing systems. Thank you.
-
Code to Stress Test Lemmy for performance
I thought some people were out there in June creating stress-testing scripts, but I haven't seen anything materializing/showing results in recent weeks?
I think it would be useful to have an API client that establishes some baseline performance number that can be run before a new release of Lemmy and at least ensure there is no performance regression?
The biggest problem I have had since day 1 is not being able to reproduce the data that lemmy.ml has inside. There is a lot of older content stored that does not get replicated, etc.
The site_aggregates UPDATE statement lacking a WHERE clause and hitting 1500 rows (number of known Lemmy instances) of data instead of 1 row is exactly the kind of data-centered problem that has slipped through the cracks. That was generating a ton of extra PostgreSQL I/O for every new comment and post from a local user.
The difficult things to take on:
-
Simulating 200 instances instead of just 5 that the current API testing code does. First, just to have 200 rows in many of the instance-specific tables so that
local = falseAPI calls are better exercised. And probably about 25 of those instances have a large number of remote subscribers to communities. -
async federation testing. The API testing in lemmy right now does immediate delivery with the API call so you don't get to find out the tricky cases of servers being unreachable.
-
Bulk loading of data. On one hand it is good to exercise the API by inserting posts and comments one at a time, but maybe loading data directly into the PostgreSQL backend would speed up development and testing?
-
The impact of scheduled jobs such as updates to certain aggregate data and post ranking for sorting. We may want to add special API feature for testing code to trigger these on-demand to stress test that concurrency with PostgreSQL isn't running into overloads.
-
Historically, there have been changes to the PostgreSQL table layout and indexes (schema) with new versions of Lemmy, which can take significant time to execute on a production server with existing data. Some kind of expectation for server operators to know how long an upgrade can take to modify data.
-
Searching on communities, posts, comments with significant amounts of data in PostgreSQL. Scanning content of large numbers of posts and comments can be done by users at any time.
-
non-Lemmy federated content in database. Possible performance and code behavior that arises from Mastodon and other non-Lemmy interactions.
I don't think it would be a big deal if the test takes 30 minutes or even longer to run.
And I'll go out and say it: Is a large Lemmy server willing to offer a copy of their database for performance troubleshooting and testing? Lemmy.ca cloned their database last Sunday which lead to the discovery of site_aggregates UPDATE without WHERE problem. Maybe we can create a procedure of how to remove private messages and get a dump once a month from a big server to analyze possible causes of PostgreSQL overloads? This may be a faster path than building up from-scratch with new testing logic.
-
-
How lemmy.ca took on finding why PostgreSQL was at 100% CPU and crashing the Lemmy website this past weekend. PostgreSQL auto_explain
IIRC, it was lemmy.ca full copy of live data that was used (copy made on development system, not live server - if I'm following). Shared Saturday July 22 on GitHub was this procedure:
...
Notable is the AUTO_EXPLAIN SQL activation statements:
``` LOAD 'auto_explain'; SET auto_explain.log_min_duration = 0; SET auto_explain.log_analyze = true; SET auto_explain.log_nested_statements = true;
```
This technique would be of great use for developers doing changes and study of PostgreSQL activity. Thank you!
-
Lemmy Server optimization of PostgreSQL by focusing on community ownership of a post - and visibility of a post in a single control field. Also local flag transition to instance_id field, with value 1
Right now querying posts has logic like this:
WHERE (((((((((("community"."removed" = $9) AND ("community"."deleted" = $10)) AND ("post"."removed" = $11)) AND ("post"."deleted" = $12)) AND (("community"."hidden" = $13)Note that a community can be hidden or deleted, separate fields. And it also has logic to see if the creator of the post is banned in the community:
LEFT OUTER JOIN "community_person_ban" ON (("post"."community_id" = "community_person_ban"."community_id") AND ("community_person_ban"."person_id" = "post"."creator_id"))And there is both a deleted boolean (end-user delete) and removed boolean (moderator removed) on a post.
Much of this also applies to comments. Which are also owned by the post, which are also owned by the community.
-
Lemmy Server Performance - is this Rust code reading the entire table of all site languages? Does it need to?
in Communities create community/edit community there is a SiteLanguage::read with no site_id, should that call to read have site_id = 1?
For reference, on my production instance my site_language table has 198460 rows and my site table has 1503 rows. Average of 132 languages per site. counts: https://lemmyadmin.bulletintree.com/query/pgcounts?output=table
-
Lemmy Server Performance, two birds with one stone, mass deletes of content: Account Delete, Community Delete, User Ban - moving these operations to a linear queue and add undo support / grace period
A general description of the proposed change and reasoning behind it is on GitHub: https://github.com/LemmyNet/lemmy/issues/3697
Linear execution of these massive changes to votes/comments/posts with concurrency awareness. Also adds a layer of social awareness, the impact on a community when a bunch of content is black-holed.
An entire site federation delete / dead server - also would fall under this umbrella of mass data change with a potential for new content ownership/etc.
-
Lemmy Server and language choices on every individual comment, many rows in the database per-community, per-site, etc. Overheard of a comment INSERT SQL
Over a short period of time, this is my incoming federation activity for new comments. pg_stat_statements output being show. It is interesting to note these two INSERT statements on comments differ only in the DEFAULT value of language column. Also note the average execution times is way higher (4.3 vs. 1.28) when the language value is set, I assume due to INDEX updates on the column? Or possibly a TRIGGER?
About half of the comments coming in from other servers have default value.
WRITES are heavy, even if it is an INDEX that has to be revised. So INSERT and UPDATE statements are important to scrutinize.
-
REQUEST community review of Lemmy Server Performance on Post Votes, Comment Votes - the most frequent database writes. Optimize?
Given how frequent these records are created, every vote by a user, I think it is important to study and review how it works.
The current design of lemmy_server 0.18.3 is to issue a SQL DELETE before (almost?) every INSERT of a new vote. The INSERT already has an UPDATE clause on it.
This is one of the few places in Lemmy that a SQL DELETE statement actually takes place. We have to be careful triggers are not firing multiple times, such as decreasing the vote to then immediately have it increase with the INSERT statement that comes later.
For insert of a comment, Lemmy doesn't seem to routinely run a DELETE before the INSERT. So why was this design chosen for votes? Likely the reason is because a user can "undo" a vote and have the record of them ever voting in the database removed. Is that the actual behavior in testing?
pg_stat_statements from an instance doing almost entirely incoming federation activity of post/comments from other instances:
-
DELETE FROM "comment_like" WHERE (("comment_like"."comment_id" = $1) AND ("comment_like"."person_id" = $2))executed 14736 times, with 607 matching records. -
INSERT INTO "comment_like" ("person_id", "comment_id", "post_id", "score") VALUES ($1, $2, $3, $4) ON CONFLICT ("comment_id", "person_id") DO UPDATE SET "person_id" = $5, "comment_id" = $6, "post_id" = $7, "score" = $8 RETURNING "comment_like"."id", "comment_like"."person_id", "comment_like"."comment_id", "comment_like"."post_id", "comment_like"."score", "comment_like"."published"executed 15883 times - each time transacting. -
update comment_aggregates ca set score = score + NEW.score, upvotes = case when NEW.score = 1 then upvotes + 1 else upvotes end, downvotes = case when NEW.score = -1 then downvotes + 1 else downvotes end where ca.comment_id = NEW.comment_idTRIGGER FUNCTION update executing 15692 times. -
update person_aggregates ua set comment_score = comment_score + NEW.score from comment c where ua.person_id = c.creator_id and c.id = NEW.comment_idTRIGGER FUNCTION update, same executions as previous.
There is some understanding to gain by the count of executions not being equal.
-
-
GREAT NEWS about Lemmy Server Performance, another major SQL mistake has been discovered today: every single comment & post create (INSERT) is updating ~1700 rows in the site_aggregates table
Details here: https://github.com/LemmyNet/lemmy/issues/3165
This will VASTLY decrease the server load of I/O for PostgreSQL, as this mistaken code is doing writes of ~1700 rows (each known Lemmy instance in the database) on every single comment & post creation. This creates record-locking issues given it is writes, which are harsh on the system. Once this is fixed, some site operators will be able to downgrade their hardware! ;)
-
Information Overload - Beehaw style
Improving Beehaw
> BLUF: The operations team at Beehaw has worked to increase site performance and uptime. This includes proactive monitoring to prevent problems from escalating and planning for future likely events.
---
Problem: Emails only sent to approved users, not denials; denied users can't reapply with the same username
- Solution: Made it so denied users get emails and their usernames freed up to re-use
Details:
-
Disabled Docker postfix container; Lemmy runs on a Linux host that can use postfix itself, without any overhead
-
Modified various postfix components to accept localhost (same system) email traffic only
-
Created two different scripts to:
- Check the Lemmy database once in while, for denied users, send them an email and delete the user from the database
- User can use the same username to register again!
- Send out emails to those users (and also, make the other Lemmy emails look nicer)
- Check the Lemmy database once in while, for denied users, send them an email and delete the user from the database
-
Sending so many emails from our provider caused the emails to end up in spam!! We had to change a bit of the outgoing flow
- DKIM and SPF setup
- Changed outgoing emails to relay through Mailgun instead of through our VPS
-
Configure Lemmy containers to use the host postfix as mail transport
All is well?
---
Problem: NO file level backups, only full image snapshots
- Solution: Procured backup storage (Backblaze B2) and setup system backups, tested restoration (successfully)
Details:
-
Requested Funds from Beehaw org to be spent on purchase of cloud based storage, B2 - approved (thank you for the donations)
-
Installed and configured restic encrypted backups of key system files -> b2 'offsite'. This means, even the data from Beehaw that is saved there, is encrypted and no one else can read that information
-
Verified scheduled backups are being run every day, to b2. Important information such as the Lemmy volumes, pictures, configurations for various services, and a database dump are included in such
-
Verified restoration works! Had a small issue with the pictrs migration to object storage (b2). Restored the entire pictrs volume from restic b2 backup successfully. Backups work!
sorry for that downtime, but hey.. it worked
---
Problem: No metrics/monitoring; what do we focus on to fix?
- Solution: Configured external system monitoring via external SNMP, internal monitoring for services/scripts
Details:
- Using an existing self-hosted Network Monitoring Solution (thus, no cost), established monitoring of Beehaw.org systems via SNMP
- This gives us important metrics such as network bandwidth usage, Memory, and CPU usage tracking down to which process are using the most, parsing system event logs and tracking disk IO/Usage
- Host based monitoring that is configured to perform actions for known error occurrences and attempts to automatically resolve them. Such as Lemmy app; crashing; again
- Alerting for unexpected events or prolonged outages. Spams the crap out of @admin and @Lionir. They love me
- Database level tracking for 'expensive' queries to know where the time and effort is spent for Lemmy. Helps us to report these issues to the developers and get it fixed.
With this information we've determined the areas to focus on are database performance and storage concerns. We'll be moving our image storage to a CDN if possible to help with bandwidth and storage costs.
Peace of mind, and let the poor admins sleep!
---
Problem: Lemmy is really slow and more resources for it are REALLY expensive
- Solution: Based on metrics (see above), tuned and configured various applications to improve performance and uptime
Details:
- I know it doesn't seem like it, but really, uptime has been better with a few exceptions
- Modified NGINX (web server) to cache items and load balance between UI instances (currently running 2 lemmy-ui containers)
- Setup frontend varnish cache to decrease backend (Lemmy/DB) load. Save images and other content before hitting the webserver; saves on CPU resources and connections, but no savings to bandwidth cost
- Artificially restricting resource usage (memory, CPU) to prove that Lemmy can run on less hardware without a ton of problems. Need to reduce the cost of running Beehaw
THE DATABASE
This gets it's own section. Look, the largest issue with Lemmy performance is currently the database. We've spent a lot of time attempting to track down why and what it is, and then fixing what we reliably can. However, none of us are rust developers or database admins. We know where Lemmy spends its time in the DB but not why and really don't know how to fix it in the code. If you've complained about why is Lemmy/Beehaw so slow this is it; this is the reason.
So since I can't code rust, what do we do? Fix it where we can! Postgresql server setting tuning and changes. Changed the following items in postgresql to give better performance based on our load and hardware:
huge_pages = on # requires sysctl.conf changes and a system reboot shared_buffers = 2GB max_connections = 150 work_mem = 3MB maintenance_work_mem = 256MB temp_file_limit = 4GB min_wal_size = 1GB max_wal_size = 4GB effective_cache_size = 3GB random_page_cost = 1.2 wal_buffers = 16MB bgwriter_delay = 100ms bgwriter_lru_maxpages = 150 effective_io_concurrency = 200 max_worker_processes = 4 max_parallel_workers_per_gather = 2 max_parallel_maintenance_workers = 2 max_parallel_workers = 6 synchronous_commit = off shared_preload_libraries = 'pg_stat_statements' pg_stat_statements.track = all---Now I'm not saying all of these had an affect, or even a cumulative affect; just the values we've changed. Be sure to use your own system values and not copy the above. The three largest changes I'd say are key to do are
synchronous_commit = off,huge_pages = onandwork_mem = 3MB. This article may help you understand a few of those changes.With these changes, the database seems to be working a damn sight better even under heavier loads. There are still a lot of inefficiencies that can be fixed with the Lemmy app for these queries. A user phiresky has made some huge improvements there and we're hoping to see those pulled into main Lemmy on the next full release.
---
Problem: Lemmy errors aren't helpful and sometimes don't even reach the user (UI)
- Solution: Make our own UI with
blackjack and hookerspropagation for backend Lemmy errors. Some of these fixes have been merged into Lemmy main codebase
Details
- Yeah, we did that. Including some other UI niceties. Main thing is, you need to pull in the lemmy-ui code make your changes locally, and then use that custom image as your UI for docker
- Made some changes to a custom lemmy-ui image such as handling a few JSON parsed error better, improving feedback given to the user
- Remove and/or move some elements around, change the CSS spacing
- Change the node server to listen to system signals sent to it, such as a graceful docker restart
- Other minor changes to assist caching, changed the container image to Debian based instead of Alpine (reducing crashes)
---
The end?
No, not by far. But I am about to hit the character limit for Lemmy posts. There have been many other changes and additions to Beehaw operations, these are but a few of the key changes. Sharing with the broader community so those of you also running Lemmy, can see if these changes help you too. Ask questions and I'll discuss and answer what I can; no secret sauce or passwords though; I'm not ChatGPT.
Shout out to @[email protected] , @[email protected] and @[email protected] for continuing to work with me to keep Beehaw running smoothly.
Thanks all you Beeple, for being here and putting up with our growing pains!
-
Lemmy scaling/performance: Move expensive PostgreSQL triggers to scheduled jobs. · GitHub Issue #3528 · LemmyNet/lemmy
github.com Move expensive DB triggers to scheduled jobs. · Issue #3528 · LemmyNet/lemmyRequirements Is this a bug report? For questions or discussions use https://lemmy.ml/c/lemmy_support Did you check to see if this issue already exists? Is this only a single bug? Do not put multipl...

-
lemmy_server Rust code now exposes internal metrics via Prometheus endpoint
github.com Add Prometheus endpoint (#3456) · LemmyNet/lemmy@1e99e8bAdd a server for serving Prometheus metrics. Include a configuration block in the config file. Provide HTTP metrics on the API, along with process-level metrics and DB pool metrics.

-
Big Lemmy server lemmy.world has put into production critical performance fixes from a runaway SQL query identified by analyzing pg_stat_statements output - and greatly reduced their server overload!
lemmy.world Lemmy.world status update 2023-07-05 - Lemmy.worldAnother day, another update. More troubleshooting was done today. What did we do: - Yesterday evening @phiresky@[email protected] [https://lemmy.world/u/phiresky] did some SQL troubleshooting with some of the lemmy.world admins. After that, phiresky submitted some PRs to github. - @[email protected]...
-
De-facto memory leak
It looks like the lack of persistent storage for the federated activity queue is leading to instances running out of memory in a matter of hours. See my comment for more details.
Furthermore, this leads to data loss, since there is no other consistency mechanism. I think it might be a high priority issue, taking into account the current momentum behind growth of Lemmy...
-
lemmy PERFORMANCE CRISIS: Rust code in pull requests is starting to use moka caching crate
https://docs.rs/moka/latest/moka/
-
Lemmy PERFORMANCE CRISIS: popular instances with many remote instances following big communities could stop federating outbound for Votes on comments/posts - code path identified
I spent several hours tracing in production (updating the code a dozen times with extra logging) to identify the actual path the lemmy_server code uses for outbound federation of votes to subscribed servers.
Major popular servers, Beehaw, Leemy.world, Lemmy.ml - have a large number of instance servers subscribing to their communities to get copies of every post/comment. Comment votes/likes are the most common activity, and it is proposed that during the PERFORMANCE CRISIS that outbound vote/like sharing be turned off by these overwhelmed servers.
pull request for draft:
https://github.com/LemmyNet/lemmy/compare/main...RocketDerp:lemmy_comment_votes_nofed1:no_federation_of_votes_outbound0
EDIT: LEMMY_SKIP_FEDERATE_VOTES environment variable
-
PERFORMANCE OPTIMIZATION: lemmy_server Rust code all over database lookup: "= LocalSite::read"
Grep the lemmy server code for "= LocalSite::read" - and I find that even for a single vote by an end-user, it is doing an SQL query to the local site settings to see if downvotes are disabled.
Can some Rust programmers chime in here? Can we cache this in RAM and not fetch from SQL every time?
PostgreSQL is telling me that the 2nd most run query on my system, which is receiving incoming federation post/comment/votes, is this:
SELECT "local_site"."id", "local_site"."site_id", "local_site"."site_setup", "local_site"."enable_downvotes", "local_site"."enable_nsfw", "local_site"."community_creation_admin_only", "local_site"."require_email_verification", "local_site"."application_question", "local_site"."private_instance", "local_site"."default_theme", "local_site"."default_post_listing_type", "local_site"."legal_information", "local_site"."hide_modlog_mod_names", "local_site"."application_email_admins", "local_site"."slur_filter_regex", "local_site"."actor_name_max_length", "local_site"."federation_enabled", "local_site"."captcha_enabled", "local_site"."captcha_difficulty", "local_site"."published", "local_site"."updated", "local_site"."registration_mode", "local_site"."reports_email_admins" FROM "local_site" LIMIT $1 -
Admin tools
Has anyone come up with some admin tools to display anything helpful regarding servers like
Community federation status last sync pass fail etc
General db stats size etc
-
lemmy_server API for Clients and Federation alike, concurrency self-awareness, load sheding, and self-tuning
Heavy loads have been brought up several times, major social events where people flock to social media. Such as a terrorist bombing, submarine sinking, earthquake, nuclear meltdown, celebrity airplane crash, etc.
Low-budget hosting to compete with the tech giants is also a general concern for the project. Trying not to have a server that uses tons of expensive resources during some peak usage.
Load shedding and self-tuning within the code and for SysOps to have some idea if their Lemmy server is nearing overload thresholds.
See comments:
-
lemmy-ui seems to be doing database search for Post Title matches while typing every single character or edit, for performance reasons suggest an option to disable this feature be available to admins
My concern is that Lemmy is not scaling and was not tested with enough postings in the database. These "nice to have" slick UI features might have worked when the quantity of postings was much smaller, but it puts a heavy real-time load on the database to search postings that keep growing in table size every day.
I also suggest that this kind of feature be discussed with smartphone app and laternate webapp creators - as it can really busy up a server dong text pattern matches on all prior posting content.
-
Add http cache for webfingers by cetra3 · Pull Request #3317 · LemmyNet/lemmy (adding moka as an in-memory cache to Rust code)
github.com Add http cache for webfingers by cetra3 · Pull Request #3317 · LemmyNet/lemmyThis adds http caching for webfinger requests and other outgoing GET/HEAD requests from a lemmy server (such as fetching open-graph data etc..). Sets the default cache time on webfingers to 3 days...
-
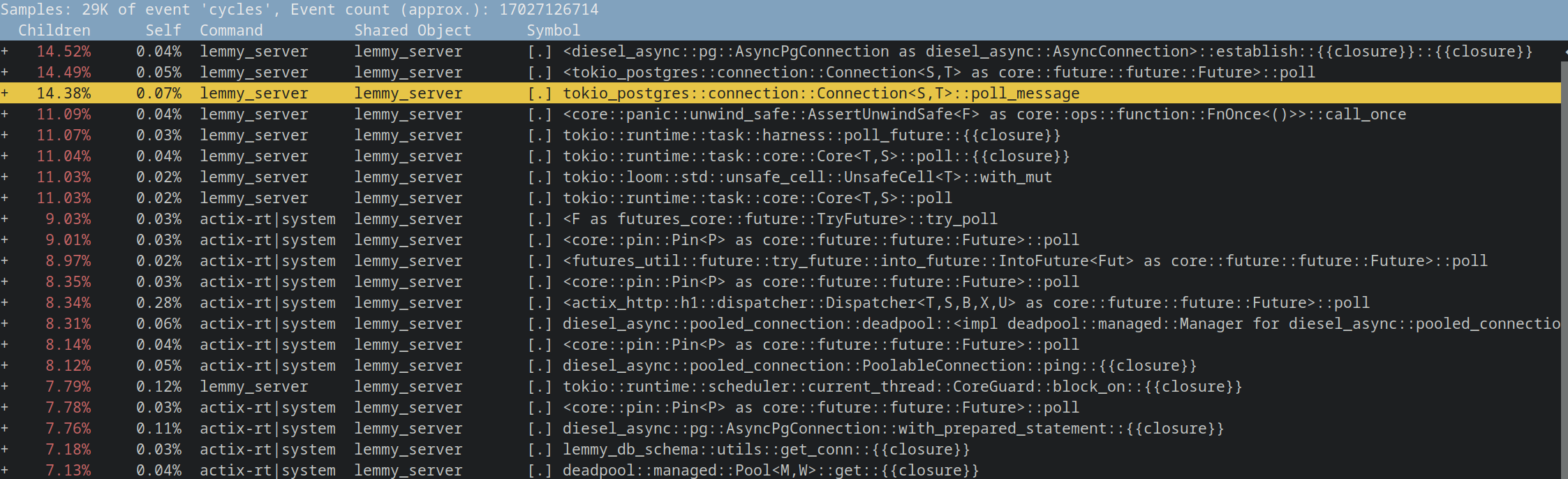
High CPU usage? How to profile Lemmy server process CPU usage
Here's how you can profile the lemmy server cpu usage with
perf(a standard linux tool):Run this to record 10 s of CPU samples:
perf record -p $(pidof lemmy_server) --call-graph=lbr -a -- sleep 10Then run this to show the output
perf report.Post your result here. There might be something obvious causing high usage.
-
Lemmy Server - full text real-time searching of all comments&posts is a performance concern. Might have worked when lemmy database was low on content.
At minimum, the Instance installer guides and documentation needs to reflect that your own server doing real-time searches should be a conscious choice.
Lemmy.ml is erroring out already on searches, GitHub issue: https://github.com/LemmyNet/lemmy/issues/3296
And if I'm seeing things right, 0.18 changed the loging from 0.17 where searching for a community https://lemmy.ml/communities now does a full-text posting/comment search? It gives a ton of output I don't want, and it's hitting the database even harder. Instead of just searching a single database table, now it is going into comments and postings.
Reddit was legendary for not having their own in-build comment and posting search engine up to date - and also used PostgreSQL (at least they did when still open source). It is a huge amount of data and I/O processing.
-
Lemmy's Rust code - interfacing to PostgreSQL, http methods for federation connections inbound and outbound
Can we get some Rust guys to chime in on the SQL wrapping that Rust is doing?
Can I butcher the Lemmy code to get the Rust code to measure the time it is taking for each SQL activity and return it in the API calls?
Also the outbound and inbound federation connections to peer servers. Can we hack in some logging on how long each of these is taking, outside the RUST_LOG stuff going on?
-
Lemmy Benchmarking - Working on tooling
Heyho,
as a PostgreSQL guy, i'm currently working an tooling environment to simulate load on a lemmy instance and measure the database usage.
The tooling is written in Go (just because it is easy to write parallel load generators with it) and i'm using tools like PoWA to have a deep look at what happens on the database.
Currently, i have some troubles with lemmy itself, that make it hard to realy stress the database. For example the worker pool is far to small to bring the database near any real performance bootlenecks. Also, Ratelimiting per IP is an issue.
I though about ignoring the reverse proxy in front of the lemmy API and just spoof Forwarded-For headers to work around it.
Any ideas are welcome. Anyone willing to help is welcome.
Goals if this should be:
- Get a good feeling for the current database usage of lemmy
- Optimize Statements and DB Layout
- Find possible improvements by caching
As your loved core devs for lemmy have large Issue Tracker backlog, some folks that talk rust fluently would be great, so we can work on this dedicated topic and provide finished PR's
Greatings, Loki (@tbe on github)
-
Lemmy PostgreSQL performance: comment_like & post_like tables have a lot of indexes (5 alone on comment_like), SQL INSERT is
taking 0.4 seconds per upvote.Federation incoming lower priority?Federation likes (votes) are wildly different from server to server as it stands now. And unless something is way off on my particular server,
0.4 seconds is what PostgreSQL is reporting as the mean (average) time per single comment vote INSERT, and post vote INSERT is similar. (NOTE: my server is classic hard drives, 100MB/sec bencharked, not a SSD)Discussion of the SQL statement for a single comment vote insert: https://lemmy.ml/post/1446775
Every single VOTE is both a HTTP transaction from the remote server and a SQL transaction. I am looking into Postgress supporting batches of inserts to not check all the index constraints at each single insert: https://www.postgresql.org/docs/current/sql-set-constraints.html
Can the Rust code for inserts from federation be reasonably modified to BEGIN TRANSACTION only every 10th comment_like INSERT and then do a COMMIT of all of them at one time? and possibly a timer that if say 15 seconds passes with no new like entries from remote servers, do a COMMIT to flush based a timeout.
Storage I/O writing for votes alone is pretty large...
-
I suspect the widespread Federation problems and 'nginx 500' errors are connected, Lemmy is swarming comments, likes to other Lemmy servers and causing a Denial of Service on peers
A single Like is measuring as taking significant time on the PostgreSQL database as a INSERT, and comments and postings are even higher. As in 1/2 second of real-time for each and every one.
The lemmy_server code that does https outbound pushes is also not thoughtful about how 20 likes against the same server hosting the community is triggering 20 simultaneous network and database connections... concurrent activity isn't considered in the queuing from how I read the current 0.17.4 code, and it blindly starts going into timing loops without considering that the same target server has too much activity.
- github.com [Architecture] Scaling federation throughput via message queues and workers · Issue #3230 · LemmyNet/lemmy
Requirements Is this a feature request? For questions or discussions use https://lemmy.ml/c/lemmy_support Did you check to see if this issue already exists? Is this only a feature request? Do not p...
![[Architecture] Scaling federation throughput via message queues and workers · Issue #3230 · LemmyNet/lemmy](https://lemmy.ml/pictrs/image/3b15f0b8-0184-4a8e-bb81-a7fee64d1563.png?format=webp&thumbnail=256)
-
nginx 500 errors to lemmy_ui webapp users, 0.17.4 era
Lemmy.ml has been giving generic nginx 500 errors on site visits for over a week. Typically it runs into periods of errors for about 1 to 5 seconds, then it clears up, to then return within 5 or 10 minutes.
I've seen them on Beehaw, I've seen them on Lemmy.world, and other reports:
https://lemmy.ml/post/1206363 https://lemmy.ml/post/1213640 https://lemmy.ml/post/1128019
Two Concerns Moving Forward
-
How can we configure nginx to give a custom error message that server admins are aware of and tracking the problem? Instead of just the generic 500 error webpage.
-
Why is lemmy_server not responding to nginx? Can we start sharing tips on how to parse the logfiles and what to look for to compile some kind of quantity of how many of these errors we are getting?
I think lemmy_server should start to keep internal error logs about in-code failure. My experience with Lemmy 0.17.4 is that it tends to conceal errors when the database transaction fails or a federationn network transaction fails. I think we need to get these errors to bubble into an organized purpose-named log and back to the end-user so they know what code path they are running into failures on and can communicate more precisely to developers and server operators.
-
-
PostgreSQL "activity" table grows large: Configurable Activity Cleanup Duration · GitHub Issue #3103 · LemmyNet/lemmy
github.com Configurable Activity Cleanup Duration · Issue #3103 · LemmyNet/lemmyDid you check to see if this issue already exists? Is this only a single feature request? Do not put multiple feature requests in one issue. Is this a question or discussion? Don't use this, use ht...

The activity has a lot of data in each row.
-
Deleting a user with lots of comments (1,59k) modding a few large communities (~20) kills the backend · Github Issue #3165 · LemmyNet/lemmy
github.com [Bug]: Deleting a user with lots of comments (1,59k) modding a few large communities (~20) kills the backend · Issue #3165 · LemmyNet/lemmyRequirements Is this a bug report? For questions or discussions use https://lemmy.ml/c/lemmy_support Did you check to see if this issue already exists? Is this only a single bug? Do not put multipl...
![[Bug]: Deleting a user with lots of comments (1,59k) modding a few large communities (~20) kills the backend · Issue #3165 · LemmyNet/lemmy](https://lemmy.ml/pictrs/image/de390664-335d-402b-9b3e-c530c44b07b7.png?format=webp&thumbnail=256)
I think it would be ideal if we discuss strategies to find these kind of database failures in the logs or even share tips on better logging design to make these kind of database failures surface to instance operators/admins.
-
Scaling federation · GitHub Issue #3062 · LemmyNet/lemmy
github.com Scaling federation · Issue #3062 · LemmyNet/lemmyYesterday I posted an announcement telling admins of large instances that they need to increase the "federation worker count". These workers are needed to send outgoing federated actions. Since the...

This closed issue has some insight into performance issues with 100+ peering partners in federation.
-
Proposal: Lemmy incoming federation data, queue to database INSERT into comments, votes and other large tables
I suggest Lemmy incoming federation inserts of votes, comments, and possibly postings - be queued so that concurrent INSERT operations into these very large database tables be kept linear so that local-instance interactive web and API (app) users are given performance priority.
This could also be a way to keep server operating costs more predictable with regard to using cloud-services for PostgreSQL.
There are several approaches that could be taken: Message Queue systems, queue to disk files, queue to an empty PostgreSQL table, queue to another database system such as SQLite, etc.
This would also start the basis for being able to accept federation incoming data while the PostgreSQL is down / website is offline for upgrades or whatever.
I would also suggest code for incoming federation data be moved to a different service and not run in-process of lemmy_server. This would be a step towards allowing replication integrity checks, backfill operations, firewall rules, CDN bypassing, etc
EDIT: And really much of this applies to outgoing, but that has gotten more attention in 0.17.4 time period - but ultimately I was speculating that the incoming backend transactions are a big part of why outbound queues are bunching up so much.
-
webapp performance concern - option for admins (and users?) to turn off home page right-column "trending communities" and "subscribed communities"
Every page hit on the posting listings / page is dynamically rendering these, doing a database query?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}